

I hate hyperbolic news headlines about data breaches, but for the “2 Billion Email Addresses” headline to be hyperbolic, it’d need to be exaggerated or overstated – and it isn’t. It’s rounded up from the more precise number of 1,957,476,021 unique email addresses, but other than that, it’s exactly what it sounds like. Oh – and 1.3 billion unique passwords, 625 million of which we’d never seen before either. It’s the most extensive corpus of data we’ve ever processed, by a significant margin.
A couple of weeks ago, I wrote about the 183M unique email addresses that Synthient had indexed in their threat intelligence platform and then shared with us. I explained that this was only part of the corpus of data they’d indexed, and that it didn’t include the credential stuffing records. Stealer log data is obtained by malware running on infected machines. In contrast, credential stuffing lists usually originate from other data breaches where email addresses and passwords are exposed. They’re then bundled up, sold, redistributed, and ultimately used to log in to victims’ accounts. Not just the accounts they were initially breached from, either, because people reuse the same password over and over again, the data from one breach is frequently usable on completely unrelated sites. A breach of a forum to comment on cats often exposes data that can then be used to log in to the victim’s shopping, social media and even email accounts. In that regard, credential stuffing data becomes “the keys to the castle”.
Let me run through how we verified the data, what you can do about it and for the tech folks, some of the hoops we had to jump through to make processing this volume of data possible.
Data Verification
The first person whose data I verified was easy – me 😔 An old email address I’ve had since the 90s has been in credential stuffing lists before, so it wasn’t too much of a surprise. Furthermore, I found a password associated with my address, which I’d definitely used many eons ago, and it was about as terrible as you’d expect from that era. However, none of the other passwords associated with my address were familiar. They certainly looked like passwords that other people might have feasibly used, but I’m pretty sure they weren’t mine. One was even just an IP address from Perth on the other side of the country, which is both infeasible as a password I would have used, yet eerily close to home. I mean, of all the places in the world an IP address could have appeared from, it had to be somewhere in my own country I’ve been many times before…
Moving on to HIBP subscribers, I reached out to a handful and asked for support verifying the data. I chose a mix of subscribers with many who’d never been involved in any data breach we’d ever seen before; my experience above suggested that there’s recycled data in there, and we had previously verified that when investigating those other incidents. However, is the all-new stuff legitimate? The very first response I received was exactly what I was looking for:
#1 is an old password that I don’t use anymore. #2 is a more recent password. Thanks for the heads up, I’ve gone and changed the password for every critical account that used either one.
Perfectly illustrating most people’s behaviour with passwords, #2 referred to above was just #1 with two exclamation marks at the end!! (Incidentally, these were simple six and eight-character passwords, and neither of them was in Pwned Passwords either.) He had three passwords in total, which also means one of them, like with my data, was not familiar. However, the most important thing here is that this example perfectly illustrates why we put the effort into processing data like this: #2 was a real, live password that this guy was actively using, and it was sitting right next to his email address, being passed around among criminals. However, through this effort, that credential pair has now become useless, which is precisely what we’re aiming for with this exercise, just a couple of billion times over.
The second respondent only had one password against their address:
Yes that was a password I used for many years for what I would call throw away or unimportant accounts between 20 and 10 years ago
That was also only eight characters, but this time, we’d seen it in Pwned Passwords many times before. And the observation about the password’s age was consistent with my own records, so there’s definitely some pretty old data in there.
The following response was not at all surprising:
I am familiar with that password… I used it almost 10 years ago… and cannot recall the last time I used it.
That was on a corporate account, too, and the owner of the address duly forwarded my email to the cybersecurity team for further investigation. The single password associated with this lady’s email address had a massive nine characters, and also hadn’t previously appeared in Pwned Passwords.
Next up was a respondent who replied inline to my questions, so I’ll list them below with the corresponding answers:
Is this familiar? Yes
Have you ever used it in the past? Yes and is still on some accounts I do not use any longer.
And if so, how long ago? Unfortunately, it is still on some active accounts that I have just made a list of to change or close immediately.
This individual’s eight-character password with uppercase, lowercase, numbers and a “special” character also wasn’t in Pwned Passwords. Similarly, as with the earlier response, that password was still in active use, posing a real risk to the owner. It would pass most password complexity criteria and slip through any service using Pwned Passwords to block bad ones, so again, this highlights why it was so important for us to process the data.
The next person had three different passwords against rows with their email address, and they came back with a now common response:
Yes, these are familiar, last used 10 years ago
We’d actually seen all three of them in Pwned Passwords before, many times each. Another respondent with precisely the kind of gamer-like passwords you’d expect a kid to use (one of which we hadn’t seen before), also confirmed (I think?) their use:
maybe when i was a kid lol
Responses that weren’t an emphatic “yes, that’s my data” were scarce. The two passwords against one person’s name were both in Pwned Passwords (albeit only once each), yet it’s entirely possible that neither of them had been used by this specific individual before. It’s also possible they’d forgotten a password they’d used more than a decade ago, or it may have even been automatically assigned to them by the service that was subsequently breached. Put it down as a statistical anomaly, but I thought it was worth mentioning to highlight that being in this data set isn’t a guarantee of a genuine password of yours being exposed. If your email address is found in this corpus then that’s real, of course, so there must be some truth in the data, but it’s a reminder that when data is aggregated from so many different sources over such a long period of time, there’s going to be some inconsistencies.
Searching Pwned Passwords
As a brief recap, we load passwords into the service we call Pwned Passwords. When we do so, there is absolutely no association between the password and the email address it appeared next to. This is for both your protection and ours; can you imagine if HIBP was pwned? It’s not beyond the realm of possibility, and the impact of exposing billions of credential pairs that can immediately unlock an untold number of accounts would be catastrophic. It’s highly risky, and completely unnecessary when you can search for standalone passwords anyway without creating the risk of it being linked back to someone.
Think about it: if you have a password of “Fido123!” and you find it’s been previously exposed (which it has), it doesn’t matter if it was exposed against your email address or someone else’s; it’s still a bad password because it’s named after your dog followed by a very predictable pattern. If you have a genuinely strong password and it’s in Pwned Passwords, then you can walk away with some confidence that it really was yours. Either way, you shouldn’t ever use that password again anywhere, and Pwned Passwords has done its job.
Checking the service is easy, anonymous and depending on your level of technical comfort, can be done in several different ways. Here’s a copy and paste from the last Synthient blog post:
- Use the Pwned Passwords search page. Passwords are protected with an anonymity model, so we never see them (it’s processed in the browser itself), but if you’re wary, just check old ones you may suspect.
- Use the k-anonymity API. This is what drives the page in the previous point, and if you’re handy with writing code, this is an easy approach and gives you complete confidence in the anonymity aspect.
- Use 1Password’s Watchtower. The password manager has a built-in checker that uses the abovementioned API and can check all the passwords in your vault. (Disclosure: 1Password is a regular sponsor of this blog, and has product placement on HIBP.)
My vested interest in 1Password aside, Watchtower is the easiest, fastest way to understand your potential exposure in this incident. And in case you’re wondering why I have so many vulnerable and reused passwords, it’s a combination of the test accounts I’ve saved over the years and the 4-digit PINs some services force you to use. Would you believe that every single 4-digit number ever has been pwned?! (If you’re interested, the ABC has a fantastic infographic using a heatmap based on HIBP data that shows some very predictable patterns for 4-digit PINs.)
This Is Not a Gmail Breach
It pains me to say it, but I have to, given the way the stealer logs made ridiculous, completely false headlines a couple of weeks ago:
This story has suddenly gained *way* more traction in recent hours, and something I thought was obvious needs clarifying: this *is not* a Gmail leak, it simply has the credentials of victims infected with malware, and Gmail is the dominant email provider: https://t.co/S75hF4T1es
— Troy Hunt (@troyhunt) October 27, 2025
There are 32 million different email domains in this latest corpus, of which gmail.com is one. It is, of course, the largest and has 394 million unique email addresses on it. In other words, 80% of the data in this corpus has absolutely nothing to do with Gmail, and the 20% of Gmail addresses have absolutely nothing to do with any sort of security vulnerability on Google’s behalf. There – now let reporting sanity prevail!
The Technical Bits
I wanted to add this just to highlight how painful it has been to deal with this data. This corpus is nearly 3 times the size of the previous largest breach we’d loaded, and HIBP is many times larger than it was in 2019 when we loaded the Collection #1 data. Taking 2 billion records and adding the ones we hadn’t already seen in the existing 15 billion corpus, whilst not adversely impacting the live system serving millions of visitors a day, was very non-trivial. Managing the nuances of SQL Server indexes such that we could optimise both inserts and queries is not my idea of fun, and it’s been a pretty hard couple of weeks if I’m honest. It’s also been a very expensive period as we turned the cloud up to 11 (we run on Azure SQL Hyperscale, which we maxed out at 80 cores for almost two weeks).
A simple example of the challenge is that after loading all the email addresses up into a staging table, we needed to create SHA1 hashes of each. Normally, that would involve something to the effect of “update table set column = sha1(email)” and you’re done. That crashed completely, so we ended up doing “insert into new table select email, sha1(email)”. But on other occasions the breach load required us to do updates on other columns (with no hash creation), which, on mulitple occasions, we had to kill after a day or more of execution with no end in sight. So, we ended up batching in loops (usually 1M records at a time), reporting on progress along the way so we had some idea of when it would actually finish. It was a painful process of trail, waiting ages, error then taking a completely different approach.
Notifying our subscribers is another problem. We have 5.9 million of them, and 2.9 million are in this data 🫨 Simply sending that many emails at once is hard. It’s not so much hard in terms of firing them off, rather it’s hard in terms of not ending up on a reputation naughty list or having mail throttled by the receiving server. That’s happened many times in the past when loading large, albeit much smaller corpuses; Gmail, for example, suddenly sees a massive spike and slows down the delivery to inboxes. Not such a biggy for sending breach notices, but a major problem for people trying to sign into their dashboard who can no longer receive the email with the “magic” link.
What we’ve done to address that for this incident is to slow down the delivery of emails for the individual breach notification. Whilst I’d originally intended to send the emails at a constant rate over the period of a week, someone listening to me on my Friday live stream had a much better suggestion:
the strategy I’ve found to best work with large email delivery is to look at the average number of emails you’ve sent over the last 30 days each time you want to ramp up, and then increase that volume by around 50% per day until you’ve worked your way through the queue
Which makes a lot of sense, and stacked up as I did more research (thanks Joe!). So, here’s what our planned delivery schedule now looks like:
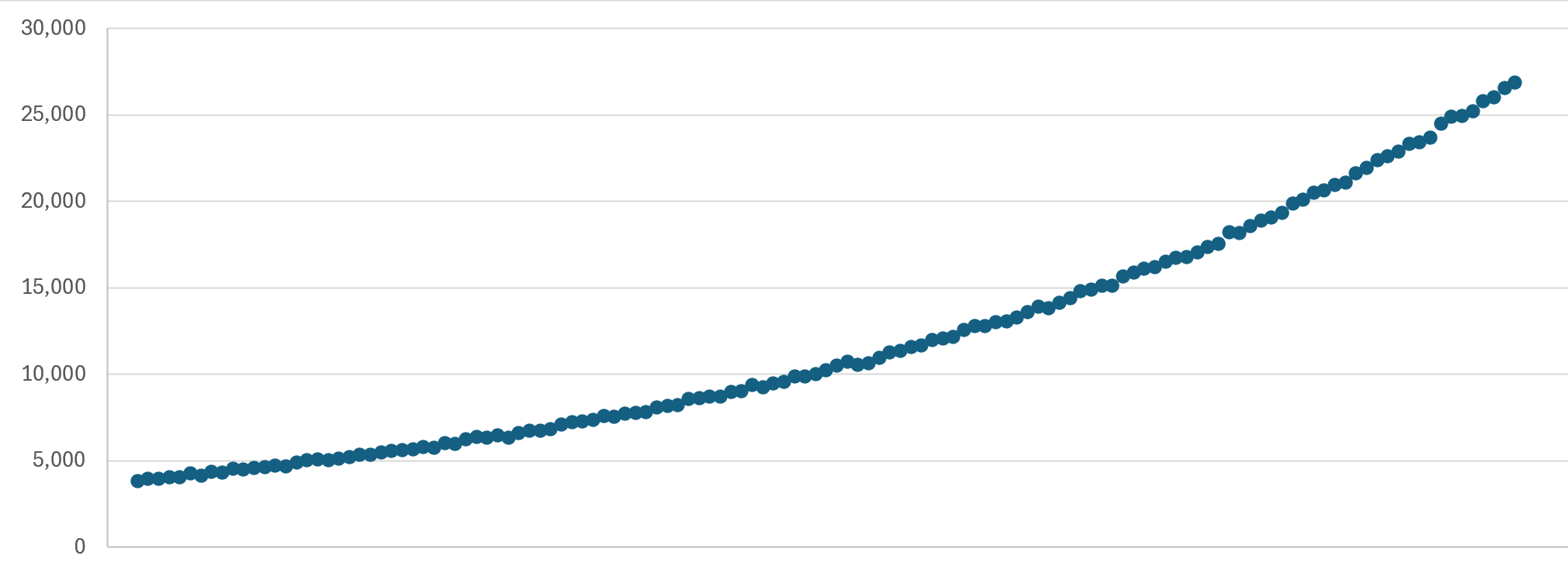
That’s broken down by hour, increasing in volume by 1.015 times per hour, such that the emails are spread out in a similar, gradually increasing cadence. On a daily basis, that works out at a 45% increase in each 24-hour period, within Joe’s suggested 50% threshold. Plus, we obviously have all the other mechanisms such as a dedicated IP, properly configured DKIM, DMARC and SPF, only emailing double-opted-in subscribers and spam-friendly message body construction. So, it could be days before you receive a notification, or just run a haveibeenpwned.com search on demand if you’re impatient.
We’ve sent all the domain notification emails instantly because, by definition, they’re going to a very wide range of different mail servers; it’s just the individual ones we’re drop-feeding.
Lastly, if you’ve integrated Pwned Passwords into your service, you’ll now see noticeably larger response sizes. The numbers I mentioned in the opening paragraph increase the size of each hash range by an average of about 50%, which will push responses from about 26kb to 40kb. That’s when brotli compressed, so obviously, make sure you’re making requests that make the most of the compression.
Conclusion
This data is now searchable in HIBP as the Synthient Credential Stuffing Threat Data. It’s an entirely separate corpus from that previous Synthient data I mentioned earlier; they’re discrete datasets with some crossover, but obviously, this one is significantly larger. And, of course, all the passwords are now searchable per the Pwned Passwords guidance above.
If I could close with one request: this was an extremely laborious, time-consuming and expensive exercise for us to complete. We’ve done our best to verify the integrity of the data and make it searchable in a practical way while remaining as privacy-centric as possible. Sending as many notifications as we have will inevitably lead to a barrage of responses from people wanting access to complete rows of data, grilling us on precisely where it was obtained from or, believe it or not, outright abusing us. Not doing those things would be awesome, and I suggest instead putting the energy into getting a password manager, making passwords strong and unique (or even better, using passkeys where available), and turning on multi-factor auth. That would be an awesome outcome for all 😊