
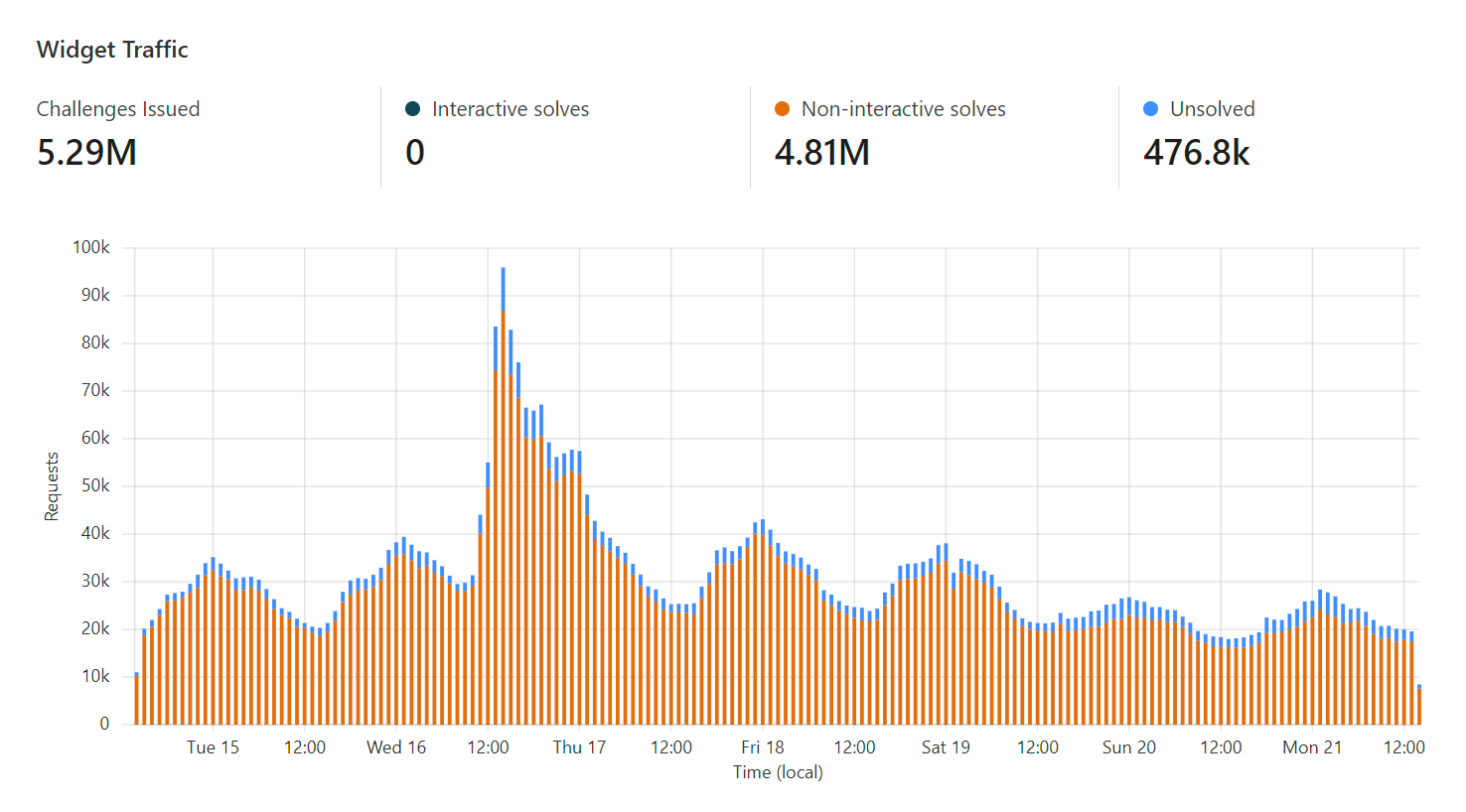
There’s a “hidden” API on HIBP. Well, it’s not “hidden” insofar as it’s easily discoverable if you watch the network traffic from the client, but it’s not meant to be called directly, rather only via the web app. It’s called “unified search” and it looks just like this:
It’s been there in one form or another since day 1 (so almost a decade now), and it serves a sole purpose: to perform searches from the home page. That is all – only from the home page. It’s called asynchronously from the client without needing to post back the entire page and by design, it’s super fast and super easy to use. Which is bad. Sometimes.
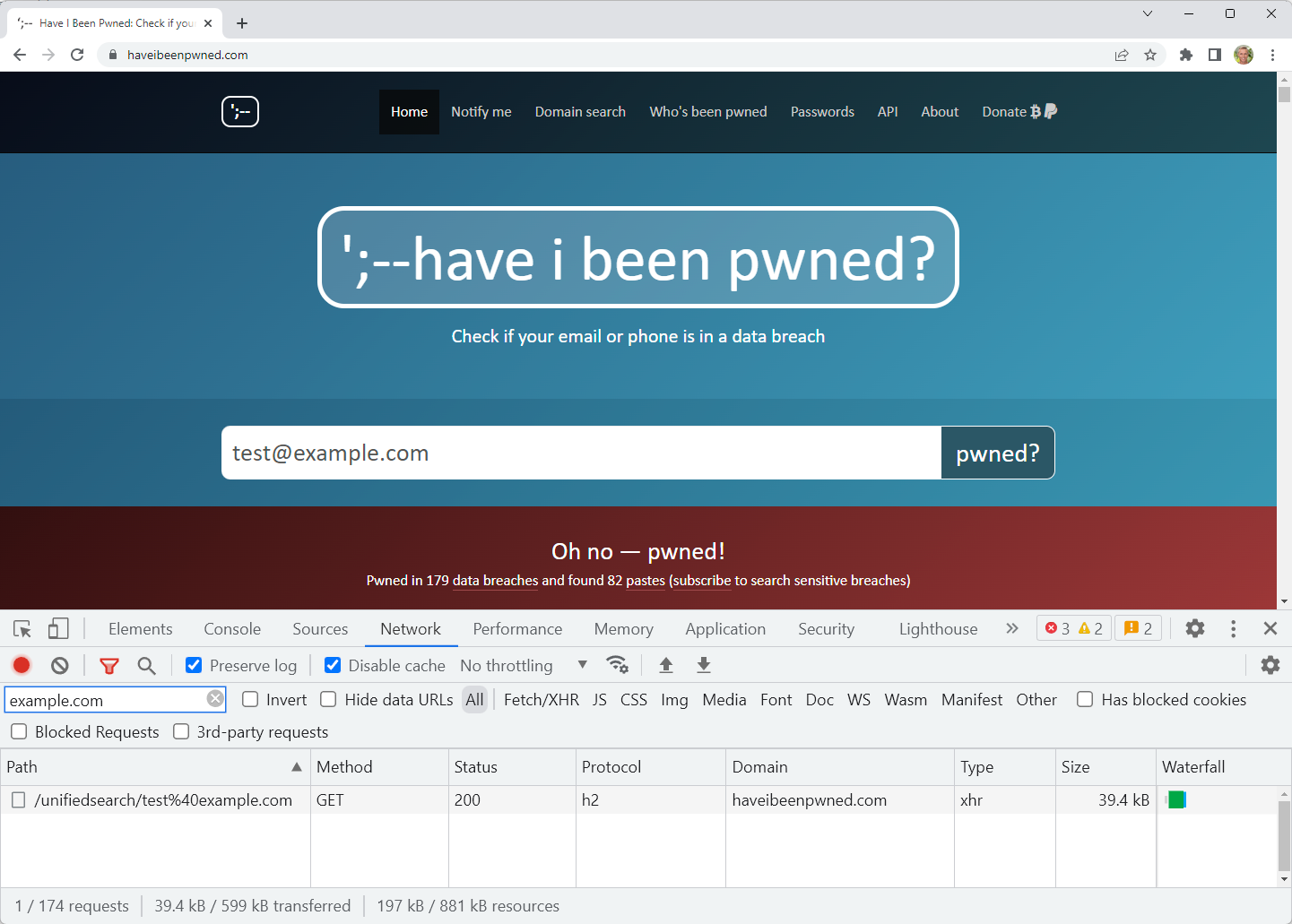
To understand why it’s bad we need to go back in time all the way to when I first launched the API that was intended to be consumed programmatically by other people’s services. That was easy, because it was basically just documenting the API that sat behind the home page of the website already, the predecessor to the one you see above. And then, unsurprisingly in retrospect, it started to be abused so I had to put a rate limit on it. Problem is, that was a very rudimentary IP-based rate limit and it could be circumvented by someone with enough IPs, so fast forward a bit further and I put auth on the API which required a nominal payment to access it. At the same time, that unified search endpoint was created and home page searches updated to use that rather than the publicly documented API. So, 2 APIs with 2 different purposes.
The primary objective for putting a price on the public API was to tackle abuse. And it did – it stopped it dead. By attaching a rate limit to a key that required a credit card to purchase it, abusive practices (namely enumerating large numbers of email addresses) disappeared. This wasn’t just about putting a financial cost to queries, it was about putting an identity cost to them; people are reluctant to start doing nasty things with a key traceable back to their own payment card! Which is why they turned their attention to the non-authenticated, non-documented unified search API.
Let’s look at a 3 day period of requests to that API earlier this year, keeping in mind this should only ever be requested organically by humans performing searches from the home page:
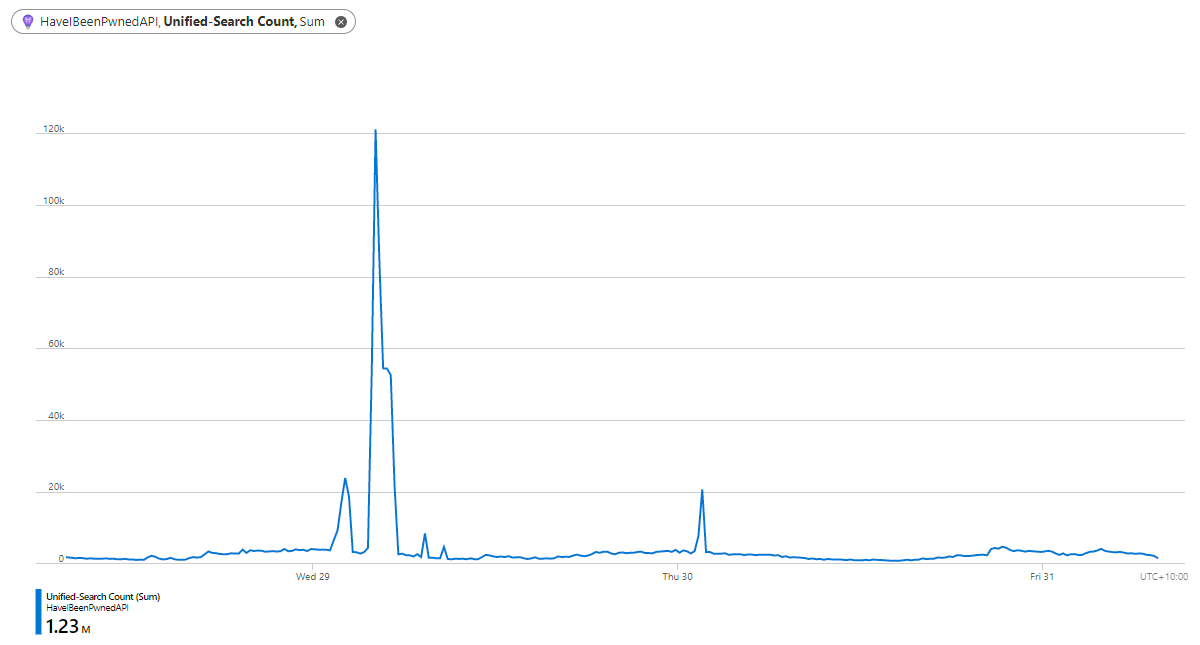
This is far from organic usage with requests peaking at 121.3k in just 5 minutes. Which poses an interesting question: how do you create an API that should only be consumed asynchronously from a web page and never programmatically via a script? You could chuck a CAPTCHA on the front page and require that be solved first but let’s face it, that’s not a pleasant user experience. Rate limit requests by IP? See the earlier problem with that. Block UA strings? Pointless, because they’re easily randomised. Rate limit an ASN? It gets you part way there, but what happens when you get a genuine flood of traffic because the site has hit the mainstream news? It happens.
Over the years, I’ve played with all sorts of combinations of firewall rules based on parameters such as geolocations with incommensurate numbers of requests to their populations, JA3 fingerprints and, of course, the parameters mentioned above. Based on the chart above these obviously didn’t catch all the abusive traffic, but they did catch a significant portion of it:
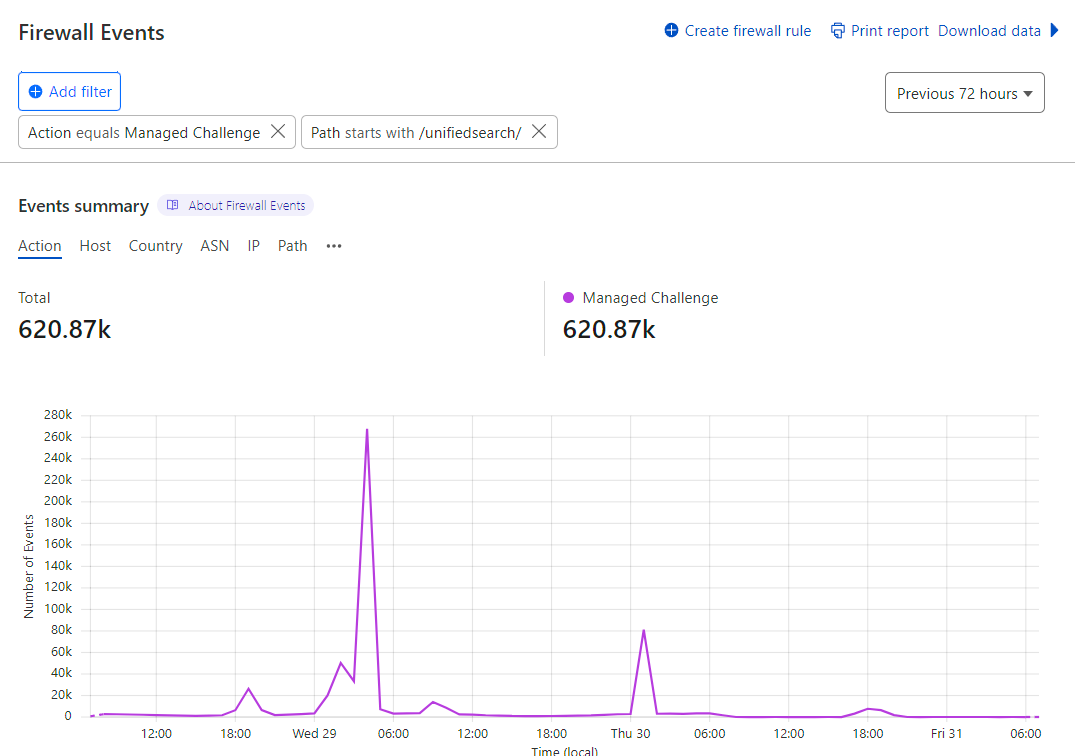
If you combine it with the previous graph, that’s about a third of all the bad traffic in that period or in other words, two thirds of the bad traffic was still getting through. There had to be a better way, which brings us to Cloudflare’s Turnstile:
With Turnstile, we adapt the actual challenge outcome to the individual visitor or browser. First, we run a series of small non-interactive JavaScript challenges gathering more signals about the visitor/browser environment. Those challenges include, proof-of-work, proof-of-space, probing for web APIs, and various other challenges for detecting browser-quirks and human behavior. As a result, we can fine-tune the difficulty of the challenge to the specific request and avoid ever showing a visual puzzle to a user.
“Avoid ever showing a visual puzzle to a user” is a polite way of saying they avoid the sucky UX of CAPTCHA. Instead, Turnstile offers the ability to issue a “non-interactive challenge” which implements the sorts of clever techniques mentioned above and as it relates to this blog post, that can be an invisible non-interactive challenge. This is one of 3 different widget types with the others being a visible non-interactive challenge and a non-intrusive interactive challenge. For my purposes on HIBP, I wanted a zero-friction implementation nobody saw, hence the invisible approach. Here’s how it works:
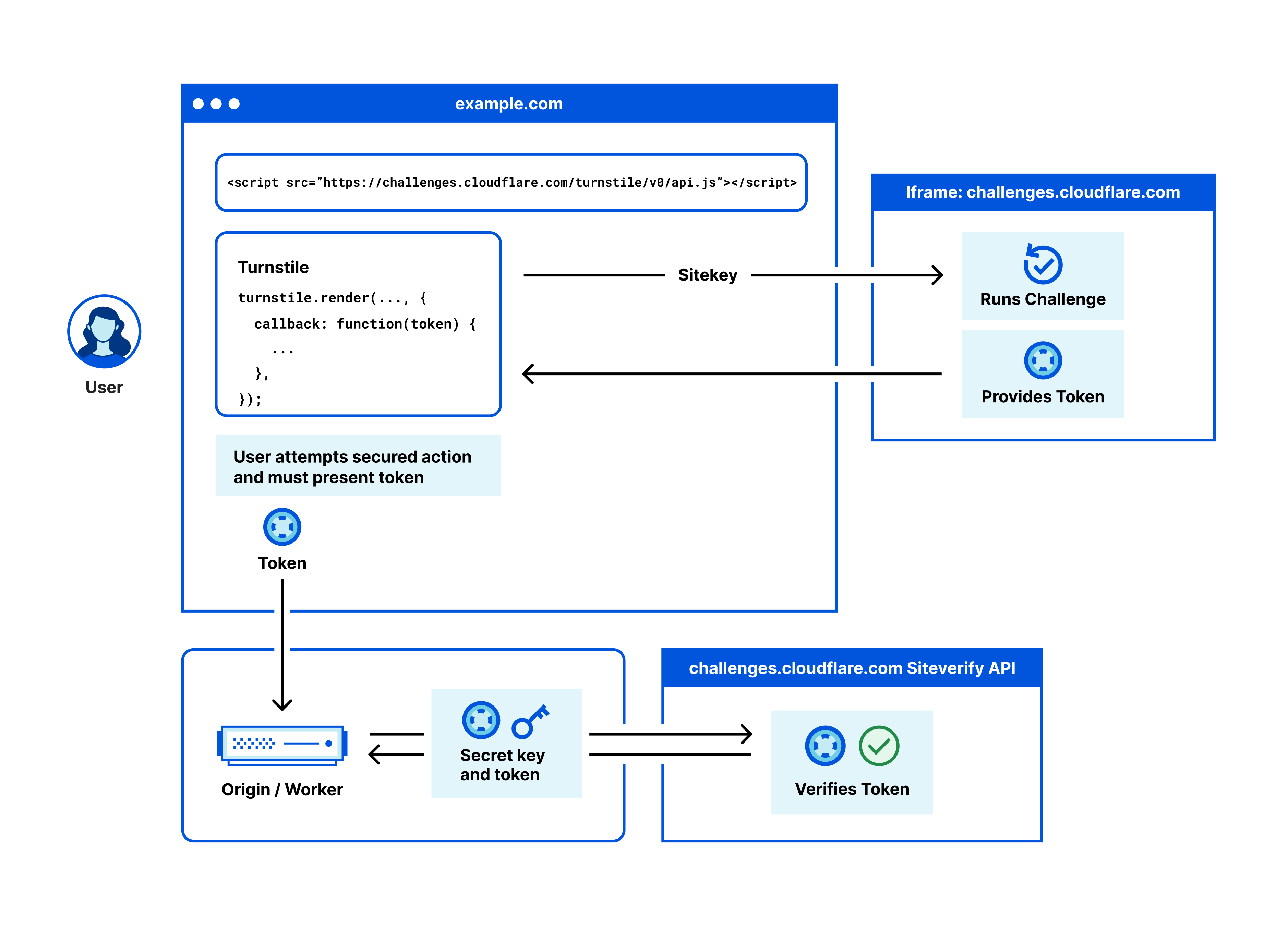
Get it? Ok, let’s break it down further as it relates to HIBP, starting with when the front page first loads and it embeds the Turnstile widget from Cloudflare:
<script src="https://challenges.cloudflare.com/turnstile/v0/api.js" async defer></script>The widget takes responsibility for running the non-interactive challenge and returning a token. This needs to be persisted somewhere on the client side which brings us to embedding the widget:
<div ID="turnstileWidget" class="cf-turnstile" data-sitekey="0x4AAAAAAADY3UwkmqCvH8VR" data-callback="turnstileCompleted"></div>Per the docs in that link, the main thing here is to have an element with the “cf-turnstile” class set on it. If you happen to go take a look at the HIBP HTML source right now, you’ll see that element precisely as it appears in the code block above. However, check it out in your browser’s dev tools so you can see how it renders in the DOM and it will look more like this:
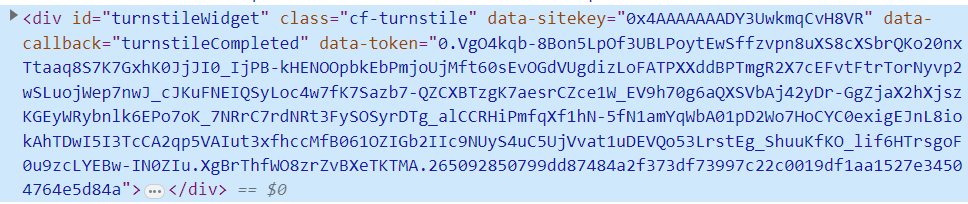
Expand that DIV tag and you’ll find a whole bunch more content set as a result of loading the widget, but that’s not relevant right now. What’s important is the data-token attribute because that’s what’s going to prove you’re not a bot when you run the search. How you implement this from here is up to you, but what HIBP does is picks up the token and sets it in the “cf-turnstile-response” header then sends it along with the request when that unified search endpoint is called:
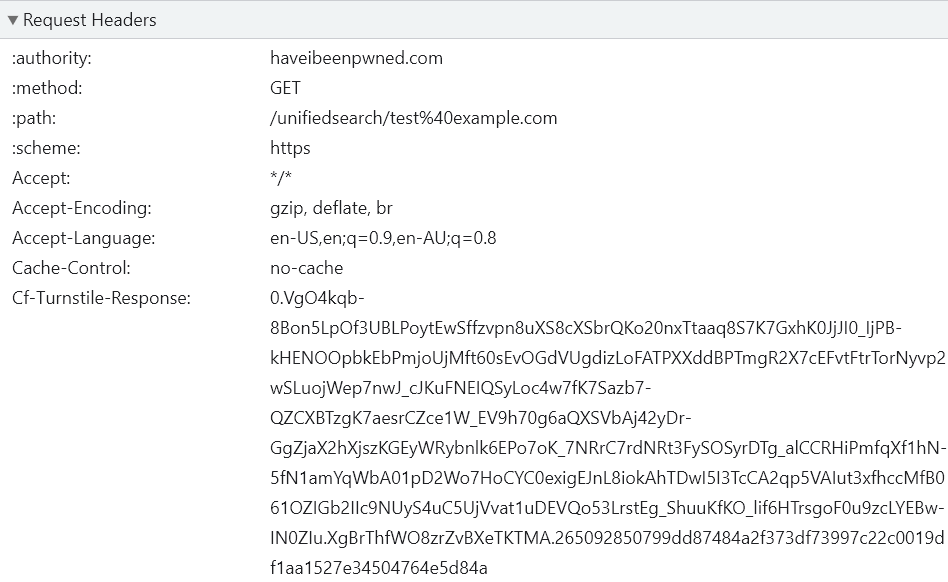
So, at this point we’ve issued a challenge, the browser has solved the challenge and received a token back, now that token has been sent along with the request for the actual resource the user wanted, in this case the unified search endpoint. The final step is to validate the token and for this I’m using a Cloudflare worker. I’ve written a lot about workers in the past so here’s the short pitch: it’s code that runs in each one of Cloudflare’s 300+ edge nodes around the world and can inspect and modify requests and responses on the fly. I already had a worker to do some other processing on unified search requests, so I just added the following:
const token = request.headers.get('cf-turnstile-response');
if (token === null) {
return new Response('Missing Turnstile token', { status: 401 });
}
const ip = request.headers.get('CF-Connecting-IP');
let formData = new FormData();
formData.append('secret', '[secret key goes here]');
formData.append('response', token);
formData.append('remoteip', ip);
const turnstileUrl = 'https://challenges.cloudflare.com/turnstile/v0/siteverify';
const result = await fetch(turnstileUrl, {
body: formData,
method: 'POST',
});
const outcome = await result.json();
if (!outcome.success) {
return new Response('Invalid Turnstile token', { status: 401 });
}That should be pretty self-explanatory and you can find the docs for this on Cloudflare’s server-side validation page which goes into more detail, but in essence, it does the following:
- Gets the token from the request header and rejects the request if it doesn’t exist
- Sends the token, your secret key and the user’s IP along to Turnstile’s “siteverify” endpoint
- If the token is not successfully verified then return 401 “Unauthorised”, otherwise continue with the request
And because this is all done in a Cloudflare worker, any of those 401 responses never even touch the origin. Not only do I not need to process the request in Azure, the person attempting to abuse my API gets a nice speedy response directly from an edge node near them ????
So, what does this mean for bots? If there’s no token then they get booted out right away. If there’s a token but it’s not valid then they get booted out at the end. But can’t they just take a previously generated token and use that? Well, yes, but only once:
If the same response is presented twice, the second and each subsequent request will generate an error stating that the response has already been consumed.
And remember, a real browser had to generate that token in the first place so it’s not like you can just automate the process of token generation then throw it at the API above. (Sidenote: that server-side validation link includes how to handle idempotency, for example when retrying failed requests.) But what if a real human fails the verification? That’s entirely up to you but in HIBP’s case, that 401 response causes a fallback to a full page post back which then implements other controls, for example an interactive challenge.
Time for graphs and stats, starting with the one in the hero image of this page where we can see the number of times Turnstile was issued and how many times it was solved over the week prior to publishing this post:
That’s a 91% hit rate of solved challenges which is great. That remaining 9% is either humans with a false positive or… bots getting rejected ????
More graphs, this time how many requests to the unified search page were rejected by Turnstile:
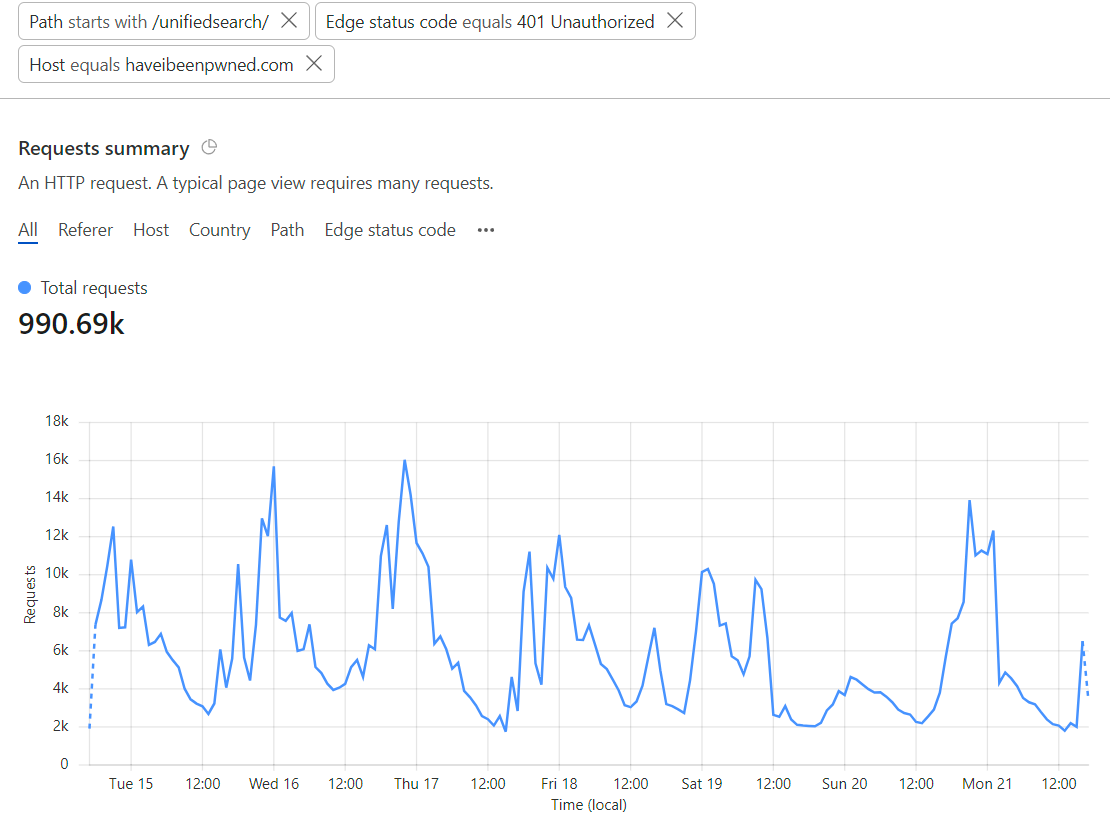
That 990k number doesn’t marry up with the 476k unsolved ones from before because they’re 2 different things: the unsolved challenges are when the Turnstile widget is loaded but not solved (hopefully due to it being a bot rather than a false positive), whereas the 401 responses to the API is when a successful (and previously unused) Turnstile token isn’t in the header. This could be because the token wasn’t present, wasn’t solved or had already been used. You get more of a sense of how many of these rejected requests were legit humans when you drill down into attributes like the JA3 fingerprints:
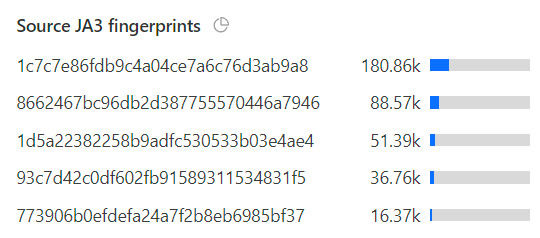
In other words, of those 990k failed requests, almost 40% of them were from the same 5 clients. Seems legit ????
And about a third were from clients with an identical UA string:
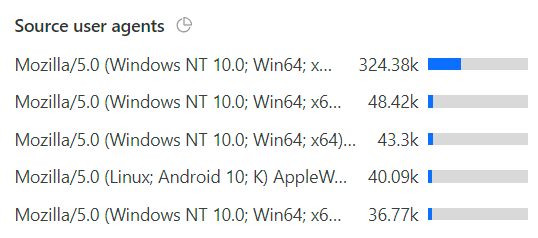
And so on and so forth. The point being that the number of actual legitimate requests from end users that were inconvenienced by Turnstile would be exceptionally small, almost certainly a very low single-digit percentage. I’ll never know exactly because bots obviously attempt to emulate legit clients and sometimes legit clients look like bots and if we could easily solve this problem then we wouldn’t need Turnstile in the first place! Anecdotally, that very small false positive number stacks up as people tend to complain pretty quickly when something isn’t optimal, and I implemented this all the way back in March. Yep, 5 months ago, and I’ve waited this long to write about it just to be confident it’s actually working. Over 100M Turnstile challenges later, I’m confident it is – I’ve not seen a single instance of abnormal traffic spikes to the unified search endpoint since rolling this out. What I did see initially though is a lot of this sort of thing:
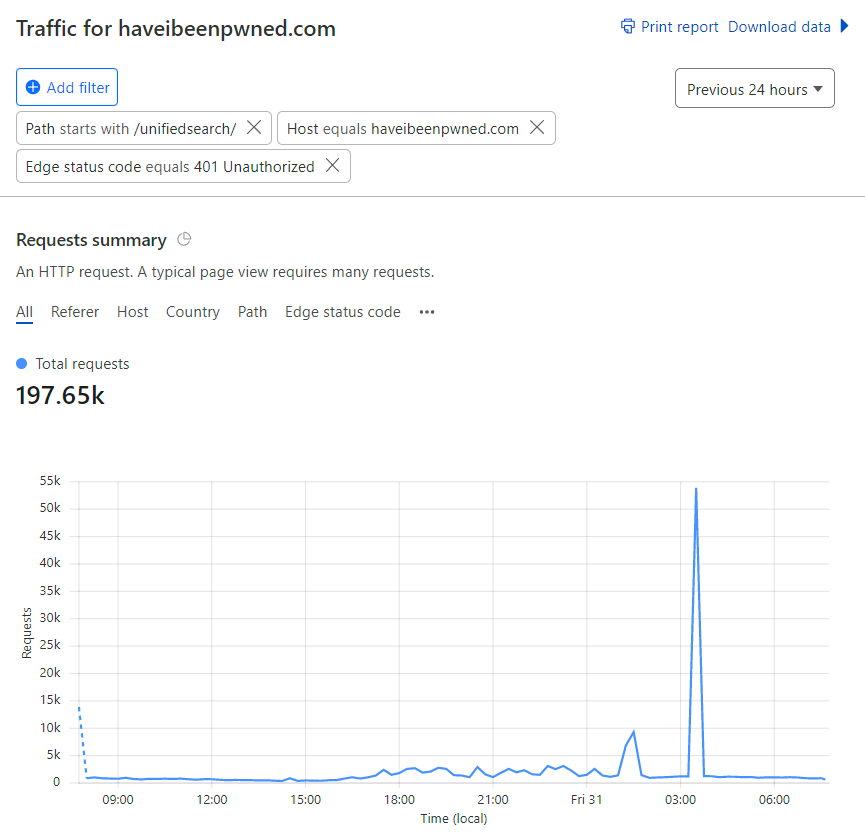
By now it should be pretty obvious what’s going on here, and it should be equally obvious that it didn’t work out real well for them ????
The bot problem is a hard one for those of us building services because we’re continually torn in different directions. We want to build a slick UX for humans but an obtrusive one for bots. We want services to be easily consumable, but only in the way we intend them to… which might be by the good bots playing by the rules!
I don’t know exactly what Cloudflare is doing in that challenge and I’ll be honest, I don’t even know what a “proof-of-space” is. But the point of using a service like this is that I don’t need to know! What I do know is that Cloudflare sees about 20% of the internet’s traffic and because of that, they’re in an unrivalled position to look at a request and make a determination on its legitimacy.
If you’re in my shoes, go and give Turnstile a go. And if you want to consume data from HIBP, go and check out the official API docs, the uh, unified search doesn’t work real well for you any more ????