
It feels like not a week goes by without someone sending me yet another credential stuffing list. It’s usually something to the effect of “hey, have you seen the Spotify breach”, to which I politely reply with a link to my old No, Spotify Wasn’t Hacked blog post (it’s just the output of a small set of credentials successfully tested against their service), and we all move on. Occasionally though, the corpus of data is of much greater significance, most notably the Collection #1 incident of early 2019. But even then, the rapid appearance of Collections #2 through #5 (and more) quickly became, as I phrased it in that blog post, “a race to the bottom” I did not want to take further part in.
Until the Naz.API list appeared. Here’s the back story: this week I was contacted by a well-known tech company that had received a bug bounty submission based on a credential stuffing list posted to a popular hacking forum:
Whilst this post dates back almost 4 months, it hadn’t come across my radar until now and inevitably, also hadn’t been sent to the aforementioned tech company. They took it seriously enough to take appropriate action against their (very sizeable) user base which gave me enough cause to investigate it further than your average cred stuffing list. Here’s what I found:
- 319 files totalling 104GB
- 70,840,771 unique email addresses
- 427,308 individual HIBP subscribers impacted
- 65.03% of addresses already in HIBP (based on a 1k random sample set)
That last number was the real kicker; when a third of the email addresses have never been seen before, that’s statistically significant. This isn’t just the usual collection of repurposed lists wrapped up with a brand-new bow on it and passed off as the next big thing; it’s a significant volume of new data. When you look at the above forum post the data accompanied, the reason why becomes clear: it’s from “stealer logs” or in other words, malware that has grabbed credentials from compromised machines. Apparently, this was sourced from the now defunct illicit.services website which (in)famously provided search results for other people’s data along these lines:
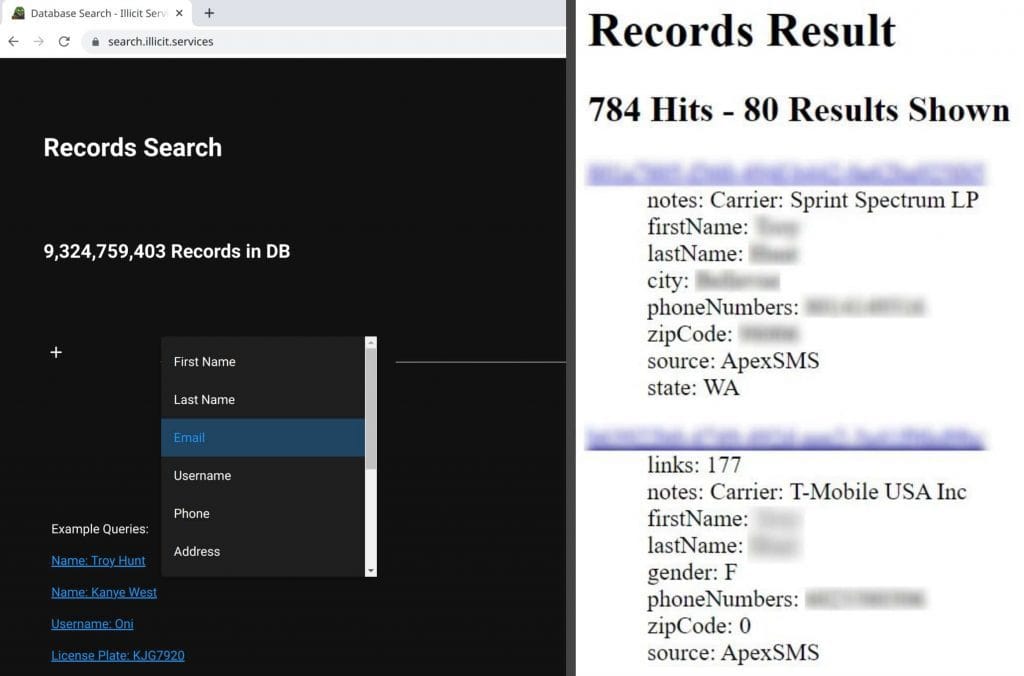
I was aware of this service because, well, just look at the first example query 🤦♂️
So, what does a stealer log look like? Website, username and password:
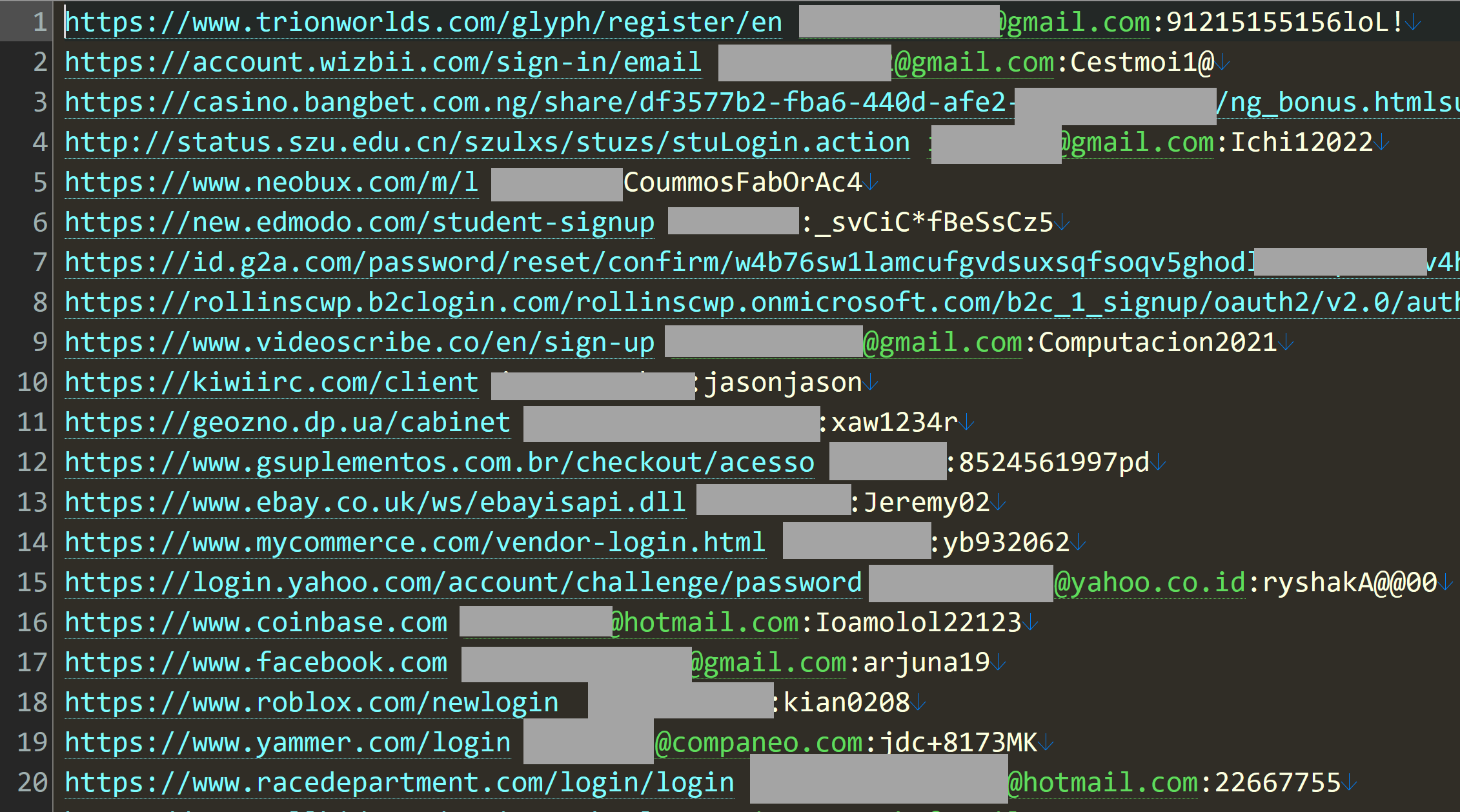
That’s just the first 20 rows out of 5 million in that particular file, but it gives you a good sense of the data. Is it legit? Whilst I won’t test a username and password pair on a service (that’s way too far into the grey for my comfort), I regularly use enumeration vectors on websites to validate whether an account actually exists or not. For example, take that last entry for racedepartment.com, head to the password reset feature and mash the keyboard to generate a (quasi) random alias @hotmail.com:
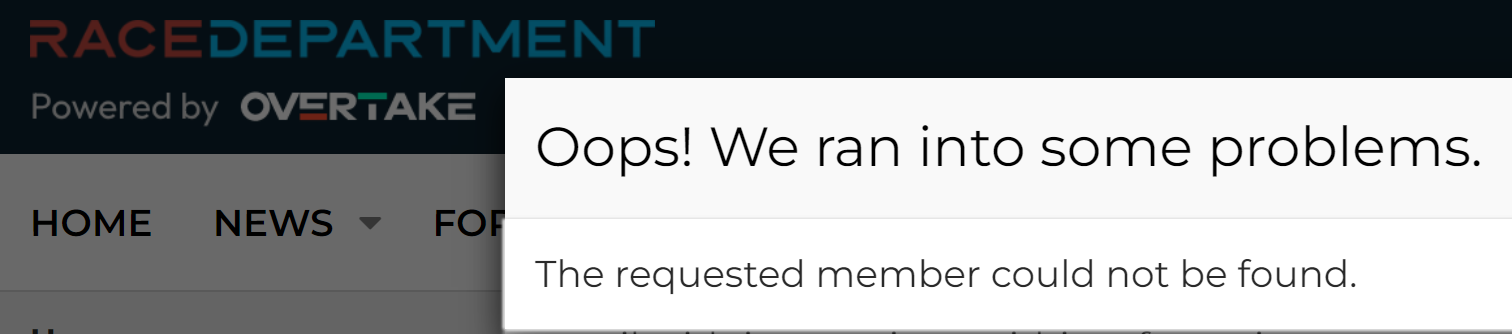
And now, with the actual Hotmail address from that last line:
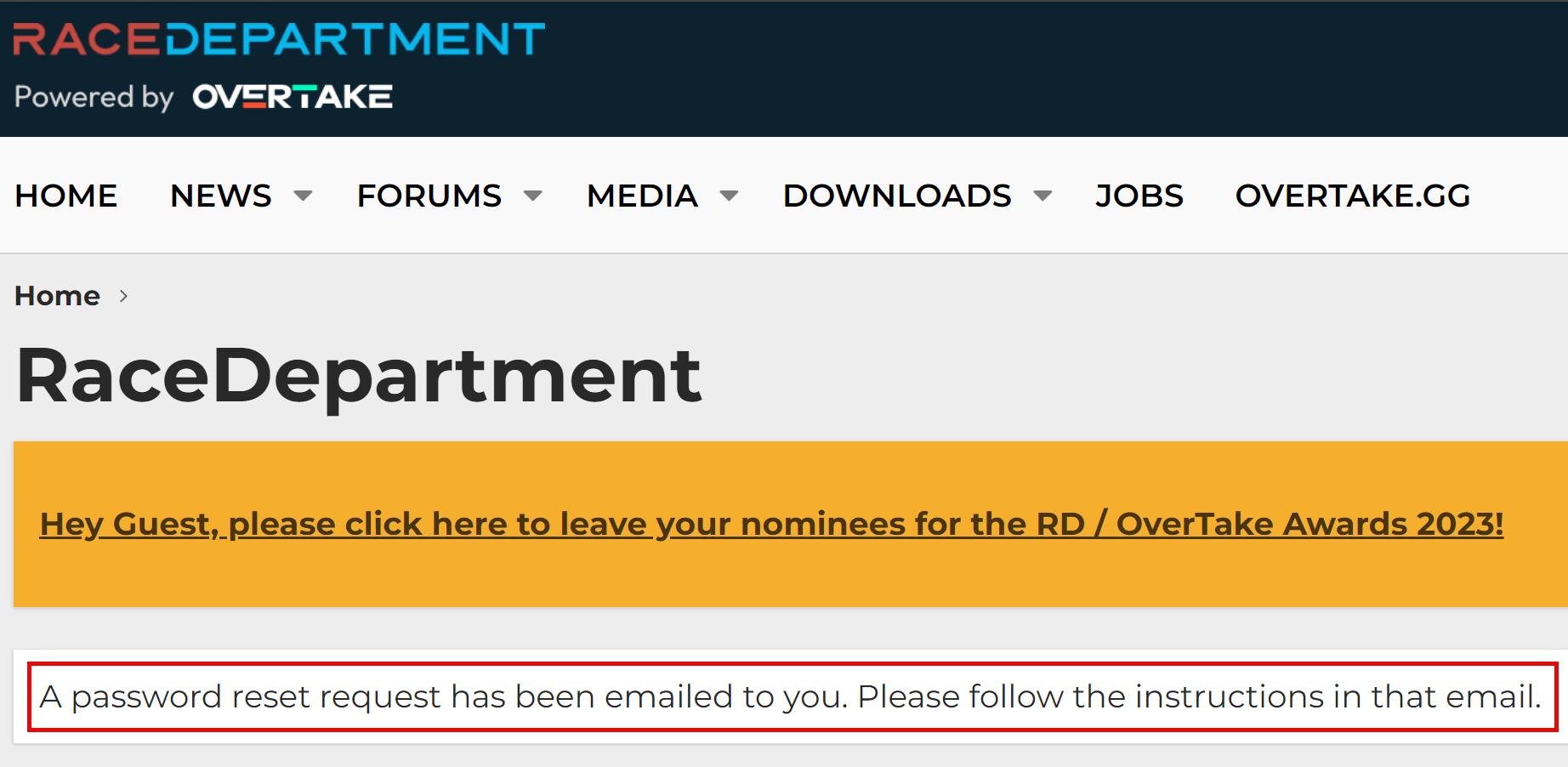
The email address exists.
The VideoScribe service on line 9:
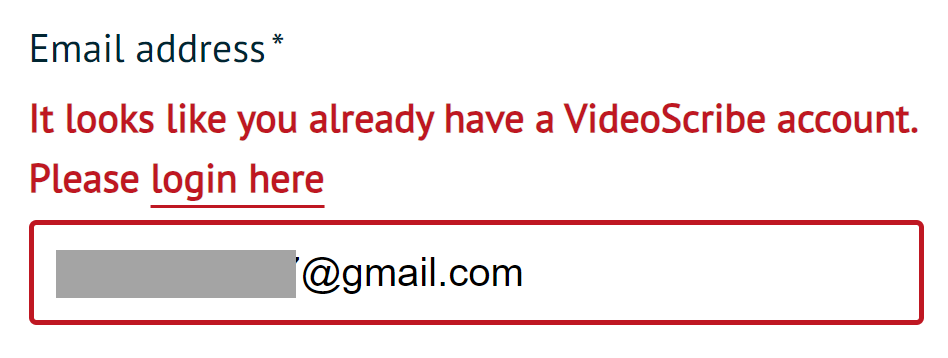
Exists.
And even the service on the very first line:
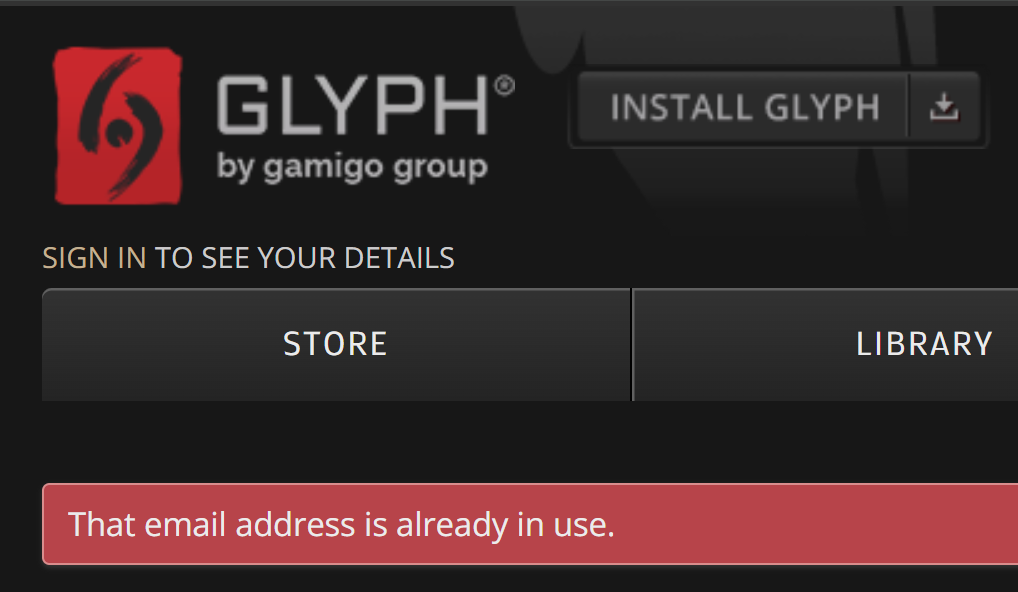
From a verification perspective, this gives me a high degree of confidence in the legitimacy of the data. The question of how valid the accompanying passwords remain aside, time and time again the email addresses in the stealer logs checked out on the services they appeared alongside.
Another technique I regularly use for validation is to reach out to impacted HIBP subscribers and simply ask them: “are you willing to help verify the legitimacy of a breach and if so, can you confirm if your data looks accurate?” I usually get pretty prompt responses:
Yes, it does. This is one of the old passwords I used for some online services.
When I asked them to date when they might have last used that password, they believed it was was either 2020 or 2021.
And another whose details appears alongside a Webex URL:
Yes, it does. but that was very old password and i used it for webex cuz i didnt care and didnt use good pass because of the fear of leaking
And another:
Yes these are passwords I have used in the past.
Which got me wondering: is my own data in there? Yep, turns out it is and with a very old password I’d genuinely used pre-2011 when I rolled over to 1Password for all my things. So that sucks, but it does help me put the incident in more context and draw an important conclusion: this corpus of data isn’t just stealer logs, it also contains your classic credential stuffing username and password pairs too. In fact, the largest file in the collection is just that: 312 million rows of email addresses and passwords.
Speaking of passwords, given the significance of this data set we’ve made sure to roll every single one of them into Pwned Passwords. Stefán has been working tirelessly the last couple of days to trawl through this massive corpus and get all the data in so that anyone hitting the k-anonymity API is already benefiting from those new passwords. And there’s a lot of them: it’s a rounding error off 100 million unique passwords that appeared 1.3 billion times across the corpus of data 😲 Now, what does that tell you about the general public’s password practices? To be fair, there are instances of duplicated rows, but there’s also a massive prevalence of people using the same password across multiple difference services and completely different people using the same password (there are a finite set of dog names and years of birth out there…) And now more than ever, the impact of this service is absolutely huge!
When we weren’t looking, @haveibeenpwned‘s Pwned Passwords rocketed past 7 *billion* requests in a month 😲 pic.twitter.com/hVDxWp3oQG
— Troy Hunt (@troyhunt) January 16, 2024
Pwned Passwords remains totally free and completely open source for both code and data so do please make use of it to the fullest extent possible. This is such an easy thing to implement, and it has a profound impact on credential stuffing attacks so if you’re running any sort of online auth service and you’re worried about the impact of Naz.API, this now completely kills any attack using that data. Password reuse remain rampant so attacks of this type prosper (23andMe’s recent incident comes immediately to mind), definitely get out in front of this one as early as you can.
So that’s the story with the Naz.API data. All the email addresses are now in HIBP and searchable either individually or via domain and all those passwords are in Pwned Passwords. There are inevitably going to be queries along the lines of “can you show me the actual password” or “which website did my record appear against” and as always, this just isn’t information we store or return in queries. That said, if you’re following the age-old guidance of using a password manager, creating strong and unique ones and turning 2FA on for all your things, this incident should be a non-event. If you’re not and you find yourself in this data, maybe this is the prompt you finally needed to go ahead and do those things right now 🙂