
So, you’ve finished your research. You developed a machine learning (ML) model, tested, and validated it and you’re now ready to start development, and then push the model to production. The hard work — the research — is finally behind you. Or is it?
Understanding the Challenges in Machine Learning Model Delivery
You suddenly think, “How can I ensure that the model will work in production as expected?”
There are multiple reasons why the model you worked so hard to develop could fail when deployed in the production environment. Below are a few:
Different data
Development and Research are not using the same databases and the data is not exactly the same. In production, inference is performed in real-time on data in memory. With research, a data lake and several query engines that work on batch data are typically used.
Different environments
Production systems use Java and C, while Research uses Python. One way around this issue is to deploy the model as a web endpoint, but sometimes performance requirements are just too strict for this solution.
Features incompatibility
There are great tools for streamlining the process of delivering a model from research to development. For example, researchers can use a feature store, in which the features are extracted in real-time and saved to a database. Researchers use the same data which will later be used by the production system and deliver an endpoint which performs the predictions. This solution is especially useful when research teams know, more or less, which features they plan on using. When the data and context shift with each project, it becomes much more difficult to work with a feature store because you need to create new features each time. It’s great for delivery, but it’s inflexible and significantly increases the overhead of changing or adding new features.
For these reasons, in some projects, the preferred delivery method is a specification document with pseudo code or a proof of concept (POC) code as a reference. The Research team delivers the document to Development and they reimplement the solution in a way that fits their system because they can’t use Research’s code as-is.
For the most part, skilled developers won’t find it difficult to implement some code based on pseudo code and specs, but the end product won’t come out exactly the same.
Development and Research will have to go through many rounds and resolve bugs to get the wanted results.
One of the main reasons why there are some differences between the Research and Development model is because the developers can’t really test their code. They can make sure it fits the specs and pseudo code, compare the final results, but they can’t properly test their code because they have no way of knowing if it functions exactly the way Research intended it to. Also, if there’s a mistake in the specification document, it will probably take a while until someone notices, if at all.
The Solution to Machine Learning Model Delivery Challenges
One way to solve this problem is to deliver tests. We’re talking about the same tests used by Research when developing the model. Testing is one way that research teams can improve the outcome of their ML model. This ensures better and more efficient outcomes, and it can be used on the end product as well. How does one deliver tests? By using a test API endpoint. When Research wants to test a functionality, they’ll implement an API endpoint that runs it, and then write a test for that API endpoint. This makes the tests language agnostic because they run against an API endpoint, not code.
The tests can then be used to validate the model created by the development team, to ensure the model in production is doing what it is supposed to. We get more from this method. Research now delivers a model and tests to Development, and it’s up to Research to keep the model and tests up-to-date, which increases Research’s ownership.
On the other hand, Development can now progress faster because they can work using a test -driven development (TDD) method which makes it easy to test code while writing it, and gain confidence that the code is ready once it passes testing. This leads to faster development because developers don’t need to constantly backtrack and recheck their code.
Why is testing a solution? Let’s reference the problems we mentioned earlier and explain how testing can solve for these common issues:
Different data
Although the initial data is different, through testing, development can tweak their code to make sure that the resulting intermediate data will be identical.
Different environments
Development uses different environments and code languages then Research, making it difficult to deliver code from one group to another. Because the tests are delivered using an API, this whole conundrum is avoided. The tests act as an intermediate language.
Testing in Machine Learning Model Delivery
We used Pytest to develop and run tests, and Flask to make the test run on a local test endpoint. Running the tests on a local endpoint lets us later replace the endpoint and run the tests on the DEV endpoint.
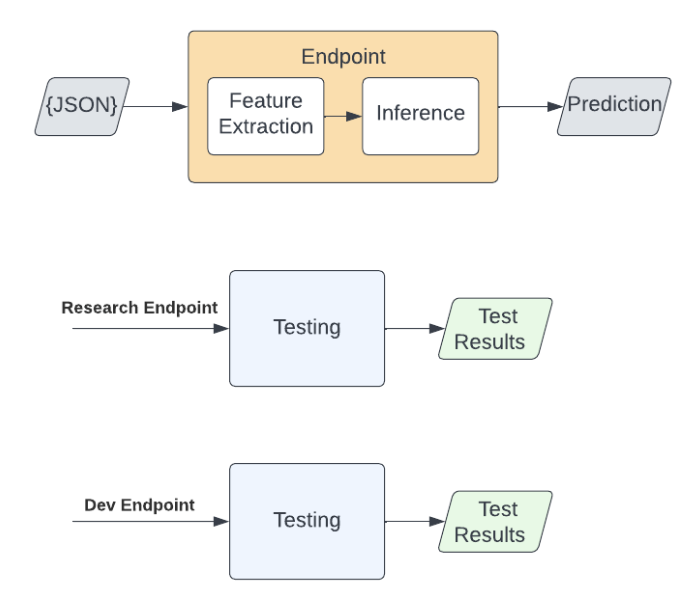
Figure 1: Testing flow
Research has to create a connector. It gets REST API calls and performs the inference and processing operations. Both operations get a DataFrame with input records and return JSON records:

Figure 2: Endpoint interface example
We use a Flask application to create a local connector implementation. The local endpoint, used by research, calls the connector functions from the tests:

Figure 3: Local endpoint implementation
Helper functions help hide the JSON serialization which makes the tests clean, as if the endpoint doesn’t exist. For example, we will use a model which gets a query string and decides whether it includes an SQL injection payload or not. Below is a model helper function and a test. In this test, an SQL injection payload is sent and the test verifies it is identified as such:

Figure 4: Helper function and a test example
Below is another example for testing the feature extraction code. The _process helper function is similar to the _inference function from the last example. The null_values is a feature which counts the number of null words:

Figure 4: Feature extraction test example
The test files are part of the model development git project. They are written and maintained as part of it.
Delivery to Development
Dev are in charge of running the tests as part of their build process. They have to wrap their model and processing code in an API and send the API endpoint to the test.
We used Docker to hide the internal test implementation. The tests are packed as a Docker image. The image contains a minimal Python runtime, along with the test’s dependencies. The test gets the endpoint as a parameter and it returns the test results ( e.g.passed, failed) and the logs.
The “ENDPOINT” environment variable is used for running the tests on a given endpoint instead of on the local test application. Here is an example of a test run on an endpoint, where the image name is sqli-ml-test:

Here are test results example:
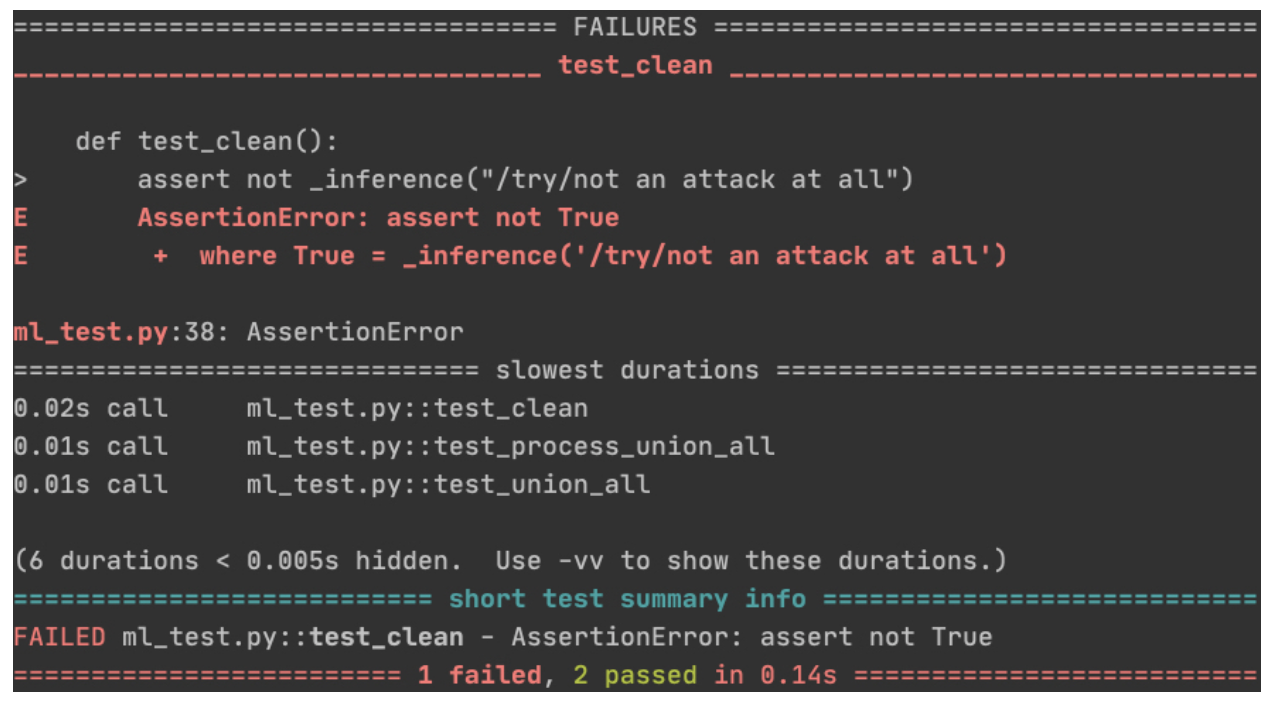
Figure 5: Pytest output example
Development can choose a version of tests to use from Git (master, or a specific branch) and run the tests. Endpoint can run on a local port. Build process can bring up the endpoint and then run the tests. Using Docker desktop, it is possible to run the tests on a PC without installing Python and dependencies.
Bug Life Cycle Flow
Tests are maintained and versioned together with the source code. They can be delivered to development on demand. Here is an example of a bug life cycle flow. After a bug is found, a test can be written by research or development. The test will run on both research and development endpoints, and updates to the code will be done accordingly.
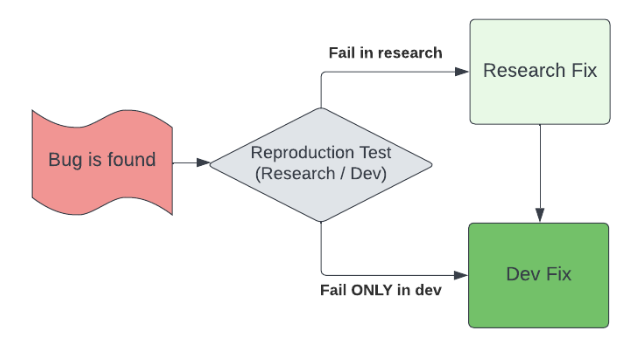
Figure 6: Bug fix flow
Summary
In order to guarantee the utility of ML models for research teams, conducting tests is crucial. By leveraging popular tools such as Pytest, Flask, git, and Docker, we successfully implemented a testing process that facilitated the transition from research to production. This allowed us to reuse the tests across both environments. These tests remained well-organized, and researchers were not affected by the fact that they were executed on a local endpoint, as this aspect remained transparent to them.
The methodology impacts researchers who continue to maintain their code, tests and ownership after the delivery. Development receives the tests, which accelerates and improves the quality of their progress.
The post Overcoming Challenges in Delivering Machine Learning Models from Research to Production appeared first on Blog.

