

I like to start long blog posts with a tl;dr, so here it is:
We’ve ingested a corpus of 1.5TB worth of stealer logs known as “ALIEN TXTBASE” into Have I Been Pwned. They contain 23 billion rows with 493 million unique website and email address pairs, affecting 284M unique email addresses. We’ve also added 244M passwords we’ve never seen before to Pwned Passwords and updated the counts against another 199M that were already in there. Finally, we now have a way for domain owners to query their entire domain for stealer logs and for website operators to identify customers who have had their email addresses snared when entering them into the site.
This work has been a month-long saga that began hot off the heels of processing the last massive stash of stealer logs in the middle of Jan. That was the first time we’d ever added more context to stealer logs by way of making the websites email addresses had been logged against searchable. To save me repeating it all here, if you’re unfamiliar with stealer logs as a concept and what we’ve previously done with HIBP, start there.
Up to speed? Good, let’s talk about ALIEN TXTBASE.
Origin Story
Last month after loading the aforementioned corpus of data, someone in a government agency reached out and pointed me in the direction of more data by way of two files totalling just over 5GB. Their file names respectively contained the numbers “703” and “704”, the word “Alien” and the following text at the beginning of each file:
Pulling the threads, it turned out the Telegram channel referred to contained 744 files of which my contact had come across just the two. The data I’m writing about today is that full corpus, published to Telegram as individual files:
A quick side note on Telegram: There’s been growing concern in recent years about the use of Telegram by organised crime, especially since the founder’s arrest in France last year for not cracking down on illegal activity on the platform. Telegram makes it super easy to publish large volumes of data (such as we’re talking about here) under the veil of anonymity and distribute it en mass. This is just one of many channels involved in cybercrime, but it’s noteworthy due to the huge amount of freely accessible data.
The file in the image above contained over 36 million rows of data consisting of website URLs and the email addresses and passwords entered into them. But the file is just a sample – a teaser – with more data available via the subscription options offered in the message. And that’s the monetisation route: provide existing data for free, then offer a subscription to feed newly obtained logs to consuming criminals with a desire to exploit the victims again. Again? The stealer logs are obtained in the first place by exploiting the victim’s machine, for example:
How do people end up in stealer logs? By doing dumb stuff like this: “Around October I downloaded a pirated version of Adobe AE and after that a trojan got into my pc” pic.twitter.com/igEzOayCu6
— Troy Hunt (@troyhunt) August 5, 2024
So now this guy has malware running on his PC which is siphoning up all his credentials as they’re entered into websites. It’s those credentials that are then sold in the stealer logs and later used to access the victim’s accounts, which is the second exploitation. Pirating software is just one way victims become infected; have a read of this recent case study from our Australian Signals Directorate:
When working from home, Alice remotely accesses the corporate network of her organisation using her personal laptop. Alice downloaded, onto her personal laptop, a version of Notepad++ from a website she believed to be legitimate. An info stealer was disguised as the installer for the Notepad++ software.
When Alice attempted to install the software, the info stealer activated and began harvesting user credentials from her laptop. This included her work username and password, which she had saved in her web browser’s saved logins feature. The info stealer then sent those user credentials to a remote command-and-control server controlled by a cybercriminal group.
Eventually, data like Alice’s ends up in places like this Telegram channel and from there, it enables further crimes. From the same ASD article:
Stolen valid user credentials are highly valuable to cybercriminals, because they expedite the initial access to corporate networks and enterprise systems.
So, that’s where the data has come from. As I said earlier, ALIEN TXTBASE is by no means the only Telegram channel out there, but it is definitely a major distribution channel.
Verification
When there’s a breach of a discrete website, verification of the incident is usually pretty trivial. For example, if Netflix suffered a breach (and I have no indication they have, this is just an example), I can go to their website, head to the password reset field, enter a made-up email address and see a response like this:
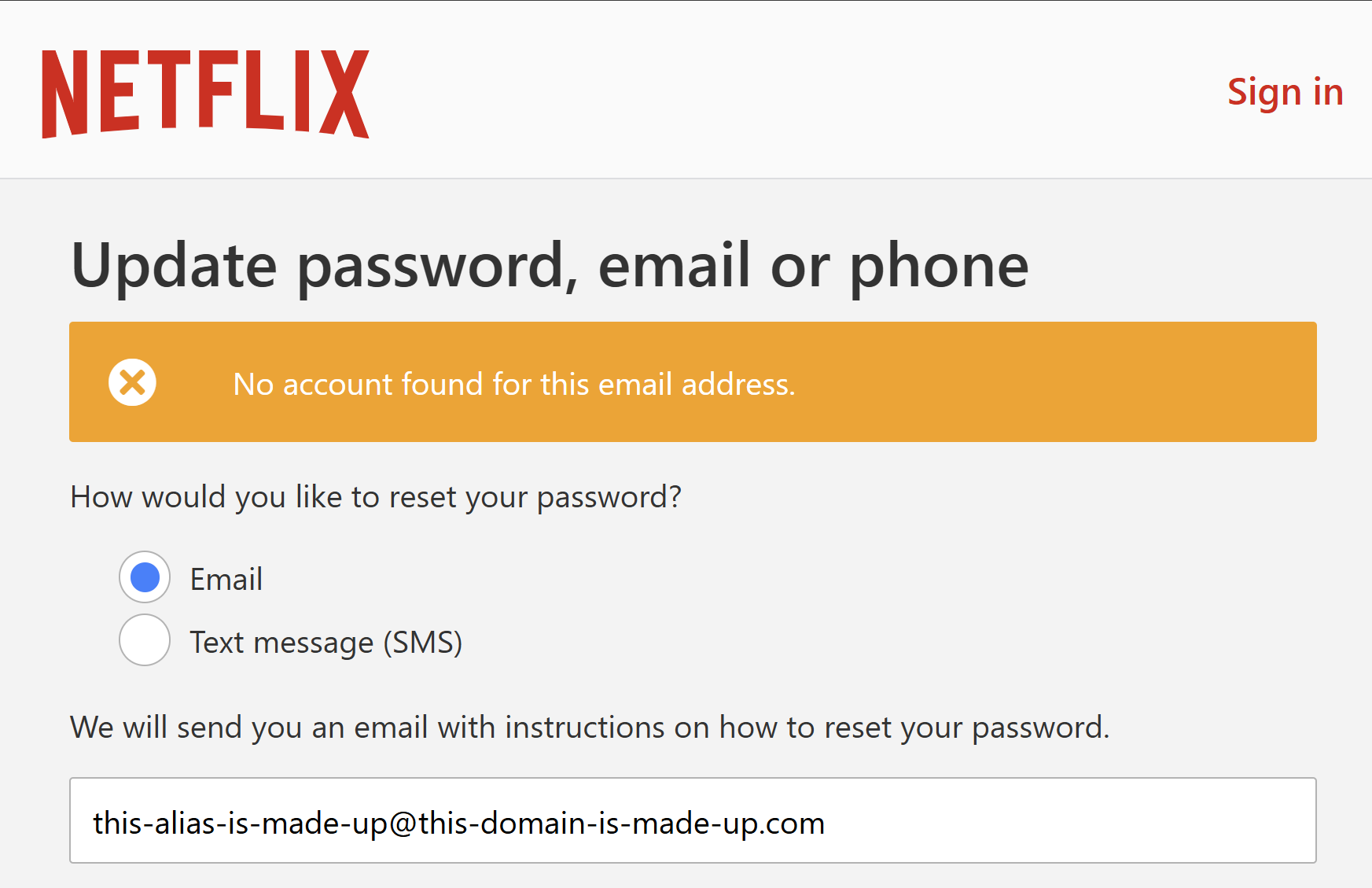
On the other hand, an address that does exist on the service usually returns a message to the effect of “we’ve sent you a password reset email”. This is called an “enumeration vector” in that it enables you to enumerate through a list of email addresses and find out which ones have an account on the site.
But stealer logs don’t come from a single source like Netflix, instead they contain the credentials for a whole range of different sites visited by people infected with malware. However, I can still take lines from the stealer logs that were captured against Netflix and test the email addresses. (Note: I never test if the password is valid, that would be a privacy violation that constitutes unauthorised access and besides, as you’ll read next, there’s simply no need to.)
Initially, I actually ran into a bit of a roadblock when testing this:
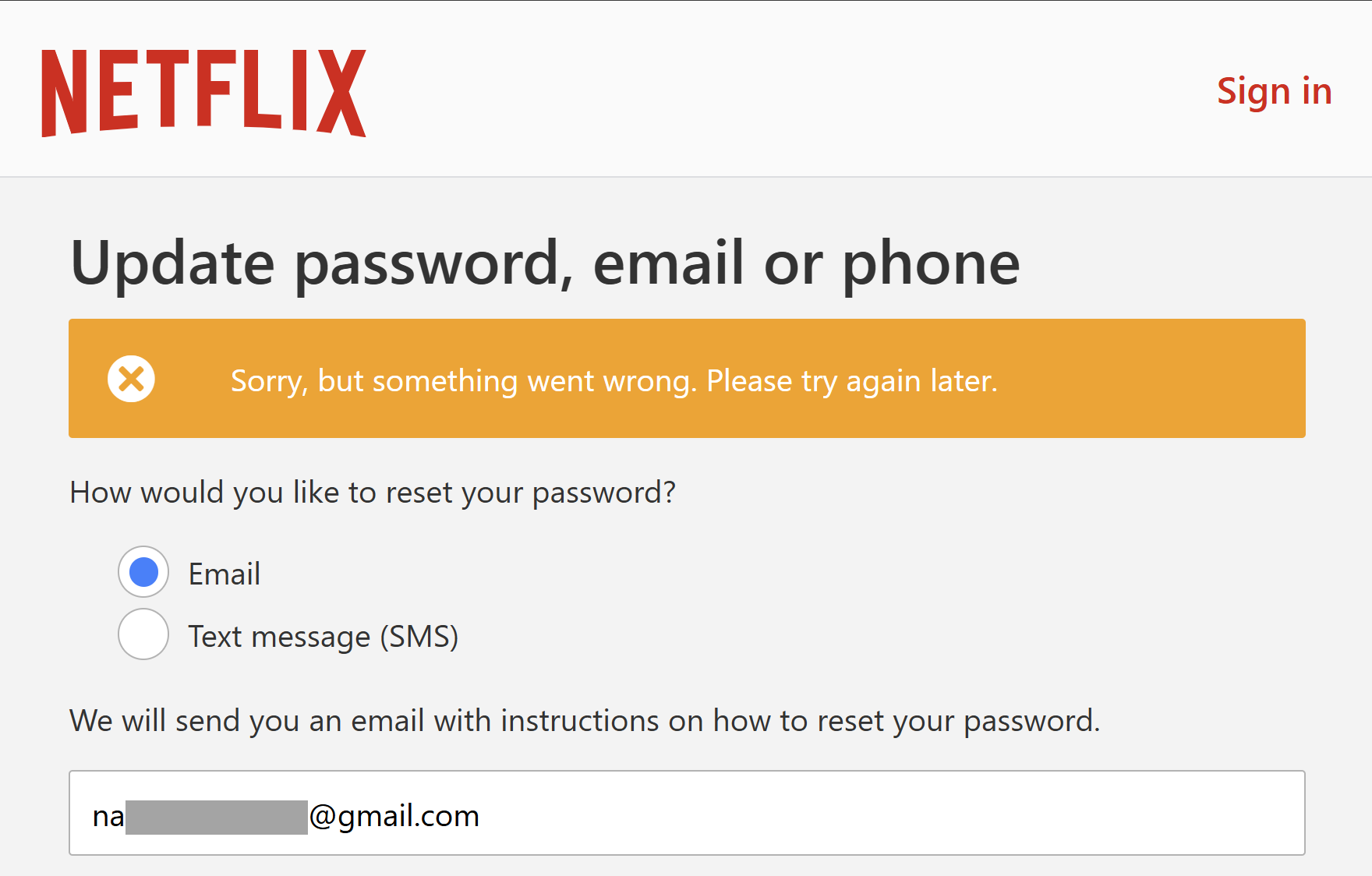
I found this over and over again so, I went back and checked the source data and inspected this poor victim’s record:

Their Netflix credentials were snared when they were entered into the website with a path of “/ph-en/login”, implying they’re likely Filipino. Let’s try VPN’ing into Manilla:
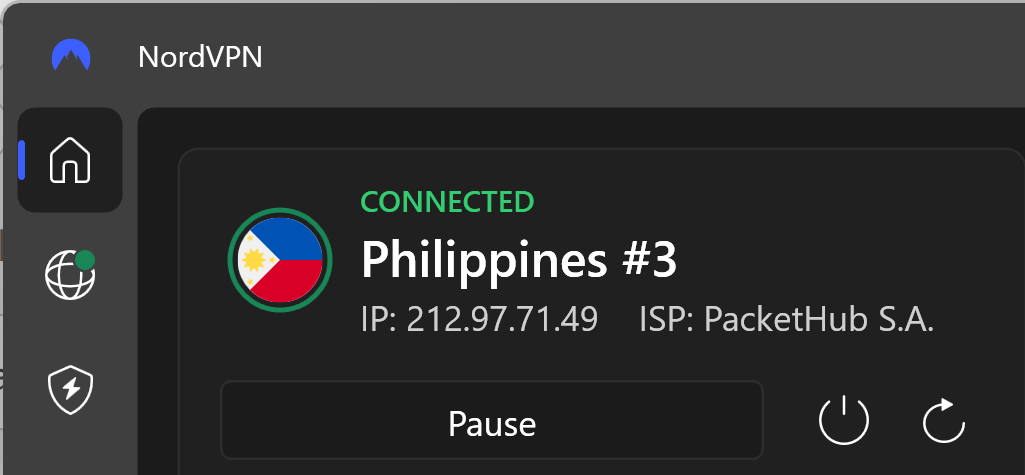
And suddenly, a password reset gives me exactly what I need:
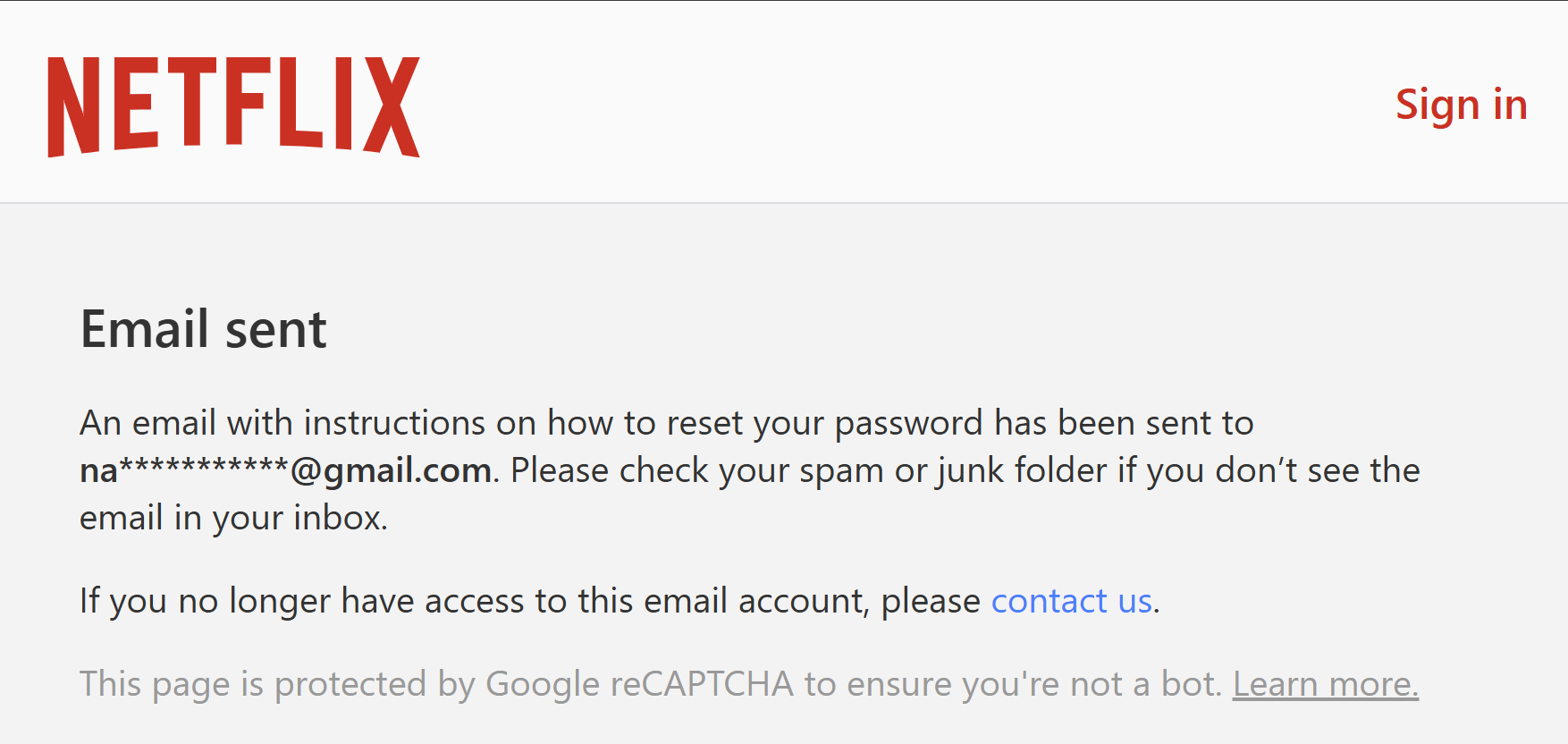
That’s a little tangent from stealer logs, but Netflix obviously applies some geo-fencing logic to certain features. This actually worked out better than expected verification-wise because not only was I able to confirm the presence of the email address on their service, but that the stealer log entry placing them in the Philippines was also geographically correct. It was reproducible too: when I saw “something went wrong”, but the path began with “mx”, I VPN’d into Mexico City and Netflix happily confirmed the reset email was sent. Another path had “ve”, so it was off to Caracas and the Venezuelan victim’s account was confirmed. You get the idea. So, strong signal on confirmation of account existence via password reset, now let’s also try something more personal.
I emailed a handful of HIBP subscribers and asked for their support verifying a breach. I got a fast, willing response from one guy and sent over more than 1,100 rows of data against his address 😲 It’s fascinating what you can tell about a person from stealer log data: He’s obviously German based on the presence of websites with a .de address, and he uses all the usual stuff most of us do (Amazon, eBay, LinkedIn, Airbnb). But it’s the less common ones that make for more interesting reading: He drives a Mercedes because he’s been logging into an address there for owners, and it also appears he likes whisky given his account at an online specialist. He’s a Firefox user, as he’s logged in there too, and he seems to be a techie as he’s logged into Seagate and a site selling some very specialised electrical testing equipment. But is it legit?

Imagine the heart-in-mouth moment the poor guy must have had seeing his digital life laid out in front of him like that and knowing criminals have this data. It’d be a hell of a shock.
Having said all that, whilst I’m confident there’s a large volume of legitimate data in this corpus, it’s also possible there will be junk. Fabricated email addresses, websites that were never used, etc. I hope folks who experience this can appreciate how hard it is for us to discern “legitimate” stealer logs from those that were made up. We’ve done as much parsing and validation as possible, but we have no way of knowing if [email protected] is an email address that actually exists or if it does, if they ever actually used Netflix or Spotify or whatever. They’re just strings of data, and all we can do is report them as found.
Searching Entries Against Your Website with a Pwned 5 Subscription
When we published the stealer logs last month, I kept caveating everything with “experimental”. Even the first word of the blog post title was “experimenting”, simply because we didn’t know how this would be received. Would people welcome the additional data we were making available? Or find it unactionable noise? It turns out it was entirely the former, and I didn’t see a single negative comment or, as it often has been in the past with stealer logs or malware breaches, angry victims demanding I send their entire row(s) of data. And I guess that makes sense given what we made available so, starting today, we’re making even more available!
First, a bit of nomenclature. Consider the following stealer log entry:
https://www.netflix.com/en-ph/login:[email protected]:P@ssw0rdThere are four parts to this entry that are relevant to the HIBP services I’m going to write about here:
| Email Address | ||||||
| Website Domain | Email Alias | Email Domain | ||||
| https:// | www.netflix.com | /en-ph/login | john | @ | example.com | P@ssw0rd |
Last month, we added functionality to the UI such that after verifying your email address you could see a collection of website domains. In the example above, this meant that John could use the free notification service to verify control of his email address after which he’d see www.netflix.com listed. (Note: we’re presently totally redesigning this as part of our UX rebuild and it’ll be much smoother in the very near future.) Likewise, we introduced an API to do exactly the same thing, but only after verifying control of the email domain. So, in the case above, the owner of example.com would be able to query [email protected] and get back www.netflix.com (along with any other website domains poor John had been using).
Today, we’re introducing two new APIs, and they’re big ones:
- Query stealer logs by email domain
- Query stealer logs by website domain
The first one is akin to our existing domain search feature so in the example above, the owner of the domain could query the stealer logs for example.com and get back each email address alias and the website domains they appear against. Here’s what that output looks like:
{
"john": [
"netflix.com"
],
"jane": [
"netflix.com",
"spotify.com"
]
}
The previous model only allowed querying by email address, so you could end up with an organisation needing to iterate through thousands of individual API requests. This model means that can now be done in a single request, which will make life much easier for larger organisations assessing the exposure of their workforce.
The second new API is designed for website operators who want to identify customers who’ve had their credentials snared at login. So, in our demo row above, Netflix could query www.netflix.com (after verifying control of the domain, of course) and retrieve a list of their customers from the stealer logs:
[
"[email protected]",
"[email protected]"
]Both these new APIs are orientated towards larger organisations and can return vast volumes of data. When considering how to price this service, the simplest, most commensurate model we arrived at was to use a pricing tier we already had: Pwned 5:

Whilst we’d previously only ever listed tiers 1 through 4, we’d always had higher tiers sitting there in the background for organisations needing higher rate limits. Surfacing this subscription and adding the ability to query stealer logs via these two new APIs makes it easy for new and existing subscribers alike to unlock the feature. And if you are an existing subscriber, the price is simply adjusted pro rata at Stripe’s end such that your existing balance is carried forward. Per the above image, this subscription is available either monthly or annually so if you just want to see what’s in the current corpus of data and keep the cost down, take it for a month then cancel it. (Note: the Pwned 5 subscription is also now required for the API to search by email address we launched last month, but the web UI that uses the notification service to show stealer log results by email is absolutely still free and will remain that way.)
Another small addition since last month is that we’ve added an “IsStealerLog” flag on the breach model. This means that anyone programmatically dealing with data in HIBP can now easily elect to handle stealer logs differently than other breaches. For example, a new breach with this flag set to “true” might then trigger a query of the new API endpoints to search by domain so that an organisation can update their records with any new stealer log entries.
Anyone searching by email domain already knows the scope of addresses on their domain as it’s reported on their dashboard. Plus, when email notifications are sent on breach load it tells you exactly how many new addresses from your domains are in the breach. Starting today, we’ve also added a column to explain how many email addresses appear against your website domain:
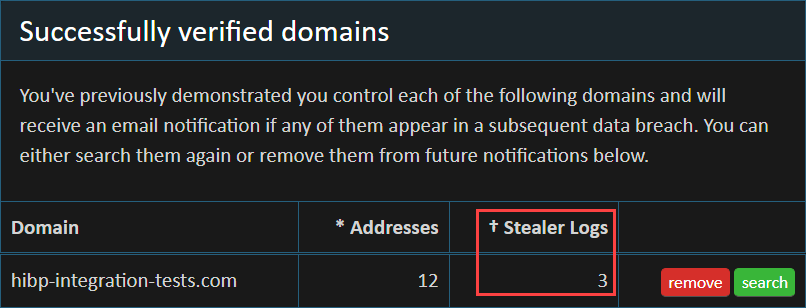
In other words, 3 people have had their email address grabbed by an info stealer when logging on to hibp-integration-tests.com, and the new API will return all of those addresses. It is only API-based for the moment, we’ll consider if a UI makes sense as part of the rebranded site launch, it may not becuase of the potentially huge volumes of data.
Just one last thing: for the two new APIs that query by domain, we’ve set a rate limit which is entirely independent of the rate limit on, say, breached account searches. Whilst a Pwned 5 subscription would allow 1,000 requests to that API every minute, it’s significantly more restricted when hitting those two new stealer log APIs. We haven’t published a number as I expect we’ll tweak it a bit based on usage, but it’s more than enough for any normal use of the service whilst ensuring we don’t get completely overwhelmed by high-overhead searches. The stealer log API that queries by email address inherits the 1,000 RPM rate limit of the Pwned 5 subscription.
We’ve Added 244M New Passwords to Pwned Passwords
One of the coolest most awesome best things we’ve ever done with HIBP is to create a massive repository of passwords that’s all open source (both code and data) and can be queried anonymously without disclosing the searched password. Pwned Passwords is amazing, and it has gained huge traction:
There it is – we’ve now passed 10,000,000,000 requests to Pwned Password in 30 days 😮 This is made possible with @Cloudflare’s support, massively edge caching the data to make it super fast and highly available for everyone. pic.twitter.com/kw3C9gsHmB
— Troy Hunt (@troyhunt) October 5, 2024
10 billion times a month, our API helps a service somewhere assist one of their customers with making a good password choice. And that’s just the API – we have no idea the full scope of the service as having the data open source means people can just download the entire corpus and run it themselves.
Per the opening para, we now have an additional 244 million previously unseen passwords in this corpus. And, as always, they make for some fun reading:
- tender-kangaroo
- swimmingkangaroo59
- gentlekangaroo
- CaptainKangaroo340
And, uh, some kangaroos doing other stuff I can’t really repeat here. Those passwords are at the final stages of loading and should flush through cache to Cloudflare’s hundreds of edge nodes in the next few hours. That’s another quarter of a billion that join the list of previously breached ones, whilst 199 million we’d already seen before have had their prevalence counts upped.
HIBP in Practice
It’s amazing to see where my little pet project with the stupid name has gone, and nobody is more surprised than me when it pops up in cool places. Looking around for some stealer log references while writing this blog post, I came across this one:
This was already in place when you created a new account or updated your password. But now it’s also verified on every login against the live HIBP database. Hats off to the tremendous service HIBP provides to the internet 🙏 https://t.co/Z61AgDaL2t
— DHH (@dhh) February 4, 2025
That’s awesome! That’s exactly the sort of use case that speaks to the motto of “do good things with breach data after bad things happen”. By adding this latest trove of data, the folks using Basecamp will immediately benefit simply by virtue of the service being plugged into our API. And sidenote: David has done some amazing stuff in the past so I was especially excited to see this shout-out 😊
This one is a similar story, albeit using Pwned Passwords:
Their service is phenomenal! We also inform users in our product if they set/change their password to a known password that has been hacked. Admins have the option to not allow for users to use these passwords, if they wish. pic.twitter.com/bvLfYm9xzH
— Brad Marshall (@iamBMarshall) February 4, 2025
Inevitably, those requests form a slice of the 10 billion monthly we see that are now able to identify a quarter of a billion more compromised ones and hopefully, keep them out of harm’s way.
For many organisations, the data we’re making available via stealer logs is the missing piece of the puzzle that explains patterns that were previously unexplainable:
Gotta say I’m pretty happy with what we did with stealer logs last week, think we’re gonna need to do more of this 😎 pic.twitter.com/4rMaMmL8LU
— Troy Hunt (@troyhunt) January 21, 2025
I’ve had so many emails to that effect after loading various stealer logs over the years. The constant theme I love hearing is how it benefits the good guys and, well, not so much the bad guys:
I love it when @haveibeenpwned screws over the bad guys 😎 pic.twitter.com/I29aMhwClW
— Troy Hunt (@troyhunt) January 16, 2025
The introduction of these new APIs today will finally help many organisations identify the source of malicious activity and even more importantly, get ahead of it and block it before it does damange. Whilst there won’t be any set cadence to the addition of more stealer logs (obviously, we can’t really predict when this stuff will emerge), I have no doubt we’ll continue to add a lot more data yet.
Techie Bits
Processing this data has been non-trivial to say the least, so I thought I’d give you a bit of an overview of how I ultimately approached it. In essence, we’re talking about transforming a very large amount of highly redundant text-based data and ultimately ending up with a distinct list of email addresses against website domains. Here’s the high-level process:
- Start with 744 files of logs totalling 1.5TB and containing 23 billion rows
- Extract all the unique email addresses from the entire corpus of stealer logs using the open source Email Address Extractor tool (284M rows)
- In a .NET console app, process each file in point 1 and extract the domain and email address from valid lines (domain, email and password, all colon delimited) to produce 744 files totalling 390GB (9.7B rows)
- In another .NET console app, consolidate all 744 files from the previous point into a single file with a distinct set of website domain and email address pairs (789M rows)
- Take the file from the previous point, and in another .NET console app, extract all the unique domains (18M rows)
- Use SQL BCP to upload the files from the two previous points to SQL Azure
- Insert any new domains that don’t already exist in HIBP (these are held in a dedicated table) via a TSQL statement (6.7M rows)
- Upload the 284M unique email addresses like with a typical data breach (69% of them were already in HIBP)
- Join the distinct list of domains and email addresses to the data uploaded in the previous point and insert email and domain pairs into the stealer log table, but only if they haven’t been seen before via another TSQL statement (493M rows)
- Wait – if I took distinct website and email pairs in step 4 and got 789M rows then in step 9 it only inserted 493M, what happened? There were 220M rows already in HIBP from last month which will account for some of the gap (existing records aren’t reinserted), and there was also some additional validation in SQL Server courtesy of code we only have in that environment. The remaining gap is explained by the .NET code not ignoring case on distinct, so in other words, I dumped and uploaded way more data than I had to and made SQL Sever do extra work 🤦♂️
- Go live and get 🍺
It was actually much, much harder than this due to the trials and errors of attempting to distil what starts out as tens of billions of rows down into hundreds of millions of unique examples. I was initially doing a lot more of the processing in SQL Azure because hey, it’s just cloud and you can turn up the performance as much as you want, right?! After running 80 cores of Azure SQL Hyperscale for days on end ($ouch$) and seeing no end in sight to the execution of queries intended to take distinct values across billions of rows, I fell back to local processing with .NET. You could, of course, use all sorts of other technologies of choice here, but it turned out that local processing with some hand-rolled code was way more efficient than delegating the task to a cloud-based RDBMS. The space used by the database tells a big part of the story:
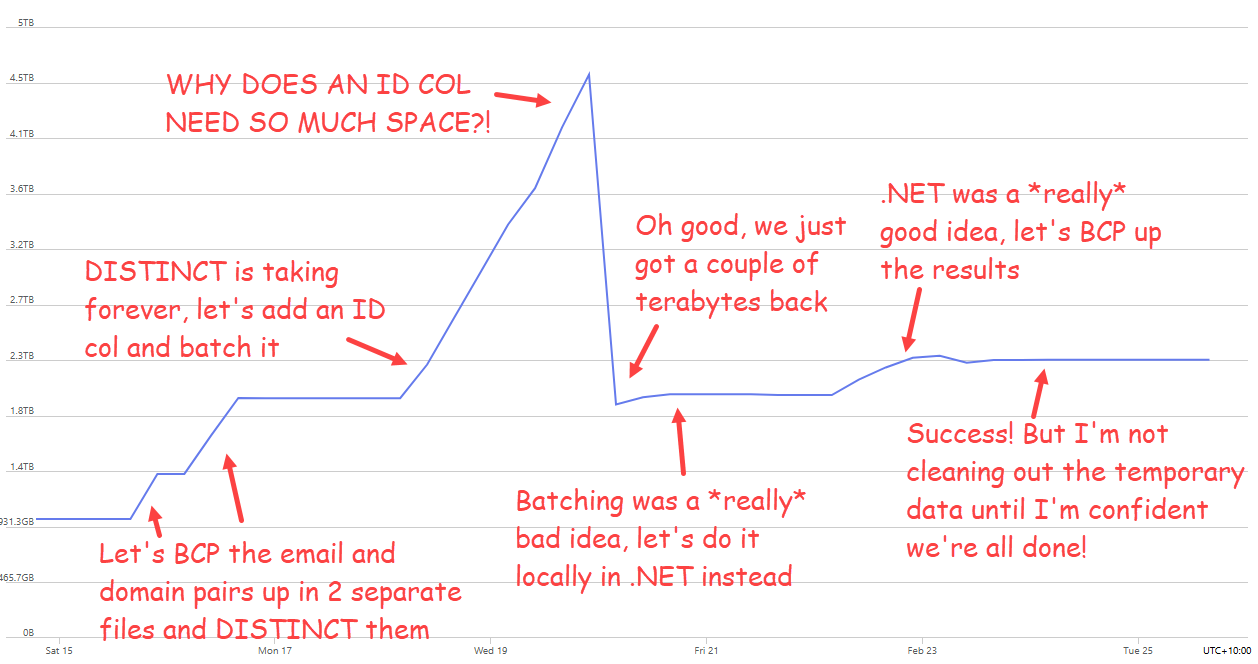
As I’ve said many times before, the cloud, my friends, is not always the answer. Do as much processing as possible locally on sunk-cost hardware unless there’s a compelling reason not to.
I’ve detailed all this here in part because that’s what I’ve always done with this project over the last 11 and a bit years, but also to illustrate how much time, effort, and money is burned processing data like this. It’s very non-trivial, especially not when everything has to ultimately go into an increasingly large system with loads of external dependencies and be fast, reliable and cost-effective.
Conclusion
From 23 billion raw rows down to a much more manageable and discrete set of data, the latest stealer logs are now searchable via all the ways you’ve done for years, plus those two new domain-based stealer log APIs. We’ve called this breach “ALIEN TXTBASE Stealer Logs”, let’s see what positive outcomes we can all now produce with the data.